публикации
2026
-
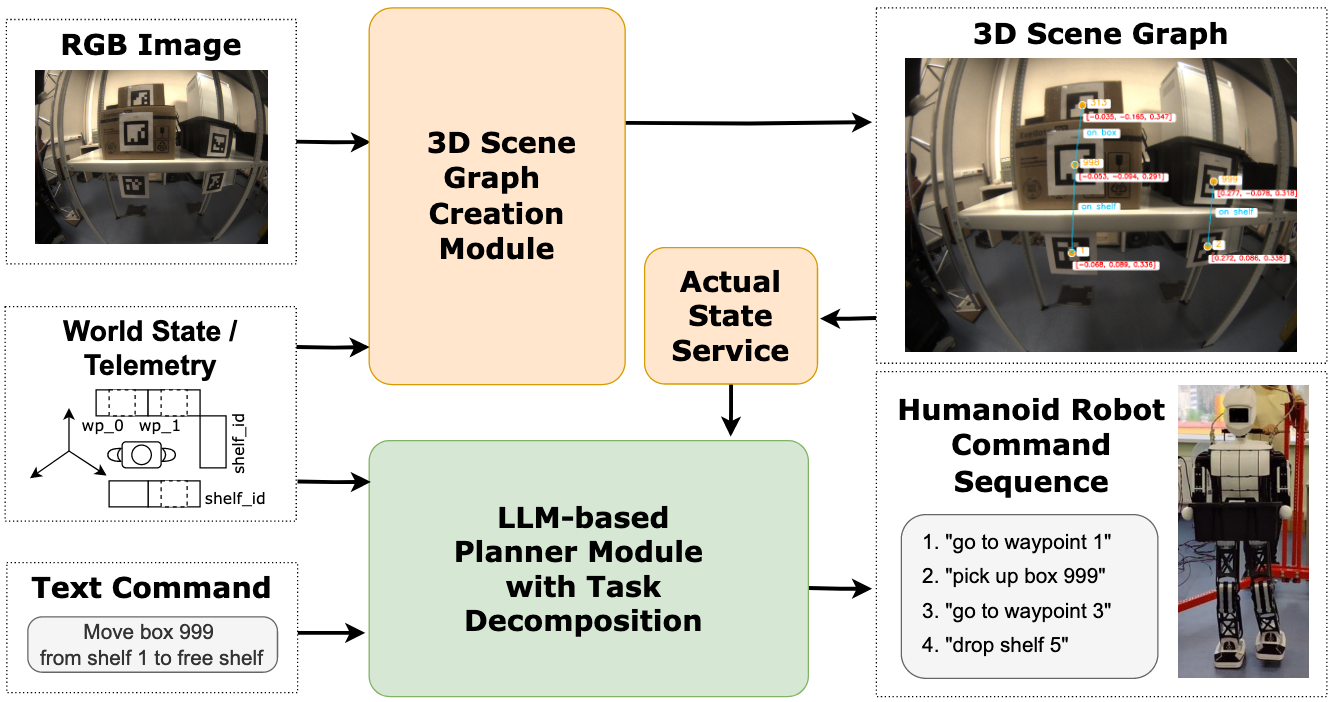 Scene graph-driven reasoning for action planning of humanoid robotDmitry Yudin, Alexander Lazarev, Eva Bakaeva, and 3 more authorsEngineering Applications of Artificial Intelligence, 2026
Scene graph-driven reasoning for action planning of humanoid robotDmitry Yudin, Alexander Lazarev, Eva Bakaeva, and 3 more authorsEngineering Applications of Artificial Intelligence, 2026@article{yudin_scene_graph_2026, dimensions = {true}, title = {Scene graph-driven reasoning for action planning of humanoid robot}, url = {https://www.sciencedirect.com/science/article/pii/S0952197626004318}, doi = {10.1016/j.engappai.2026.114150}, journal = {Engineering Applications of Artificial Intelligence}, author = {Yudin, Dmitry and Lazarev, Alexander and Bakaeva, Eva and Kochetkova, Angelika and Kovalev, Alexey and Panov, Aleksandr}, year = {2026}, volume = {169}, pages = {114150} } -
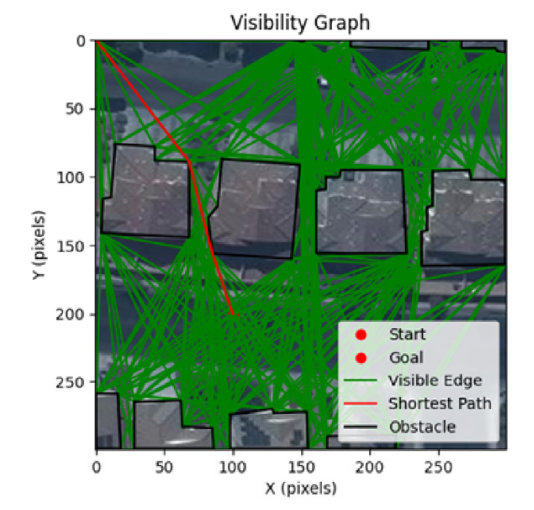 Accelerating path planning with vectorization of intersection operationsKirill Kasmynin, Konstantin Mironov, and Aleksandr PanovIntelligent Service Robotics, 2026
Accelerating path planning with vectorization of intersection operationsKirill Kasmynin, Konstantin Mironov, and Aleksandr PanovIntelligent Service Robotics, 2026@article{kasmynin_accelerating_2026, dimensions = {true}, title = {Accelerating path planning with vectorization of intersection operations}, url = {https://link.springer.com/article/10.1007/s11370-025-00680-4}, doi = {10.1007/s11370-025-00680-4}, journal = {Intelligent Service Robotics}, author = {Kasmynin, Kirill and Mironov, Konstantin and Panov, Aleksandr}, year = {2026}, volume = {19}, number = {2} }


2025
-
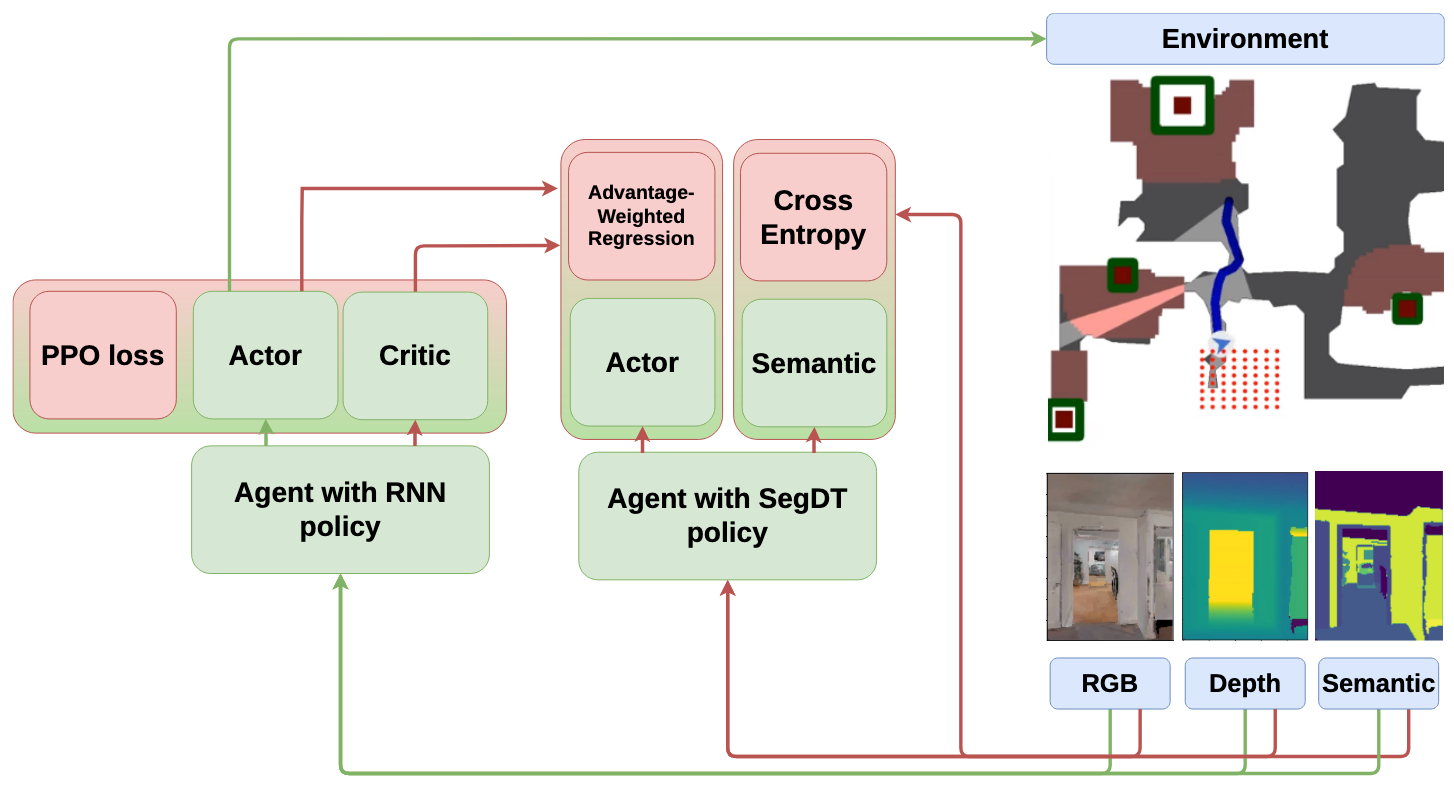 Semantic Object Navigation with Segmenting Decision TransformerAleksei Staroverov, Tatiana Zemskova, Dmitry Yudin, and 1 more authorIEEE Access, 2025
Semantic Object Navigation with Segmenting Decision TransformerAleksei Staroverov, Tatiana Zemskova, Dmitry Yudin, and 1 more authorIEEE Access, 2025Object navigation remains a fundamental challenge in robotics, particularly when agents must reach targets specified by semantic categories. While existing approaches often treat semantic understanding and navigation as separate components, we demonstrate that their tight coupling is crucial for robust performance. We present SegDT (Segmenting Decision Transformer), a novel architecture that jointly learns to predict semantic segmentation masks and navigation actions through a unified transformer-based model. Our key insight is that temporal information from sequential observations can simultaneously enhance both segmentation quality and navigation decisions. To address the inherent challenges of transformerbased navigation—notably poor sample efficiency and computational complexity—we introduce a twophase training approach: offline pretraining on expert demonstrations followed by online policy refinement through knowledge transfer from a recurrent neural network. Extensive experiments in the Habitat simulator demonstrate that SegDT achieves higher results using predicted segmentation masks, outperforming a single-frame baseline with a pre-trained semantic segmentation model and approaching the performance of systems using ground truth semantic information. Our ablation studies reveal that SegDT’s temporal processing also improves segmentation quality, highlighting the synergistic benefits of joint optimization. When integrated into complete object navigation systems, SegDT enhances overall performance by 9.6% in path efficiency compared to the state-of-the-art method. The code of SegDT is made publicly available at https://github.com/CognitiveAISystems/SegDT.
@article{staroverov_semantic_2025, dimensions = {true}, title = {Semantic {Object} {Navigation} with {Segmenting} {Decision} {Transformer}}, url = {https://ieeexplore.ieee.org/document/11153854}, journal = {IEEE Access}, author = {Staroverov, Aleksei and Zemskova, Tatiana and Yudin, Dmitry and Panov, Aleksandr}, year = {2025}, pages = {162807--162820} } -
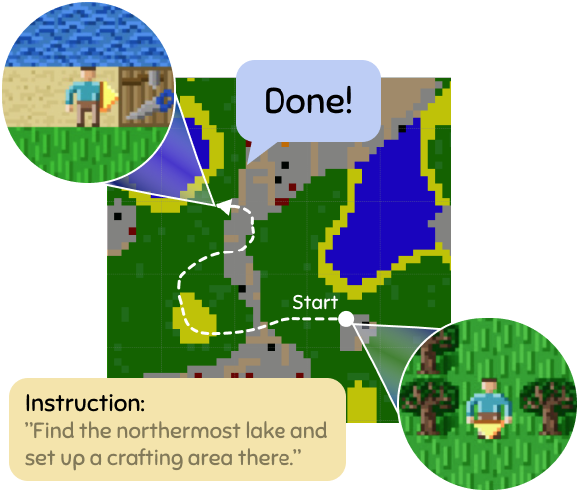 CrafText Benchmark: Advancing Instruction Following in Complex Multimodal Open-Ended WorldZoya Volovikova, Gregory Gorbov, Petr Kuderov, and 2 more authorsIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025
CrafText Benchmark: Advancing Instruction Following in Complex Multimodal Open-Ended WorldZoya Volovikova, Gregory Gorbov, Petr Kuderov, and 2 more authorsIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025Following instructions in real-world conditions requires a capability to adapt to the world’s volatility and entanglement: the environment is dynamic and unpredictable, instructions can be linguistically complex with diverse vocabulary, and the number of possible goals an agent may encounter is vast. Despite extensive research in this area, most studies are conducted in static environments with simple instructions and a limited vocabulary, making it difficult to assess agent performance in more diverse and challenging settings. To address this gap, we introduce CrafText, a benchmark for evaluating instruction following in a multimodal environment with diverse instructions and dynamic interactions. CrafText includes 3,924 instructions with 3,423 unique words, covering Localization, Conditional, Building, and Achievement tasks. Additionally, we propose an evaluation protocol that measures an agent’s ability to generalize to novel instruction formulations and dynamically evolving task configurations, providing a rigorous test of both linguistic understanding and adaptive decisionmaking.
@inproceedings{volovikova_craftext_2025, dimensions = {true}, title = {{CrafText} {Benchmark}: {Advancing} {Instruction} {Following} in {Complex} {Multimodal} {Open}-{Ended} {World}}, url = {https://aclanthology.org/2025.acl-long.1267/}, booktitle = {Proceedings of the 63rd {Annual} {Meeting} of the {Association} for {Computational} {Linguistics} ({Volume} 1: {Long} {Papers})}, author = {Volovikova, Zoya and Gorbov, Gregory and Kuderov, Petr and Panov, Aleksandr I and Skrynnik, Alexey}, year = {2025}, pages = {26131--26151} } -
 AmbiK: Dataset of Ambiguous Tasks in Kitchen EnvironmentAnastasiia Ivanova, Zoya Volovikova, Eva Bakaeva, and 2 more authorsIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025
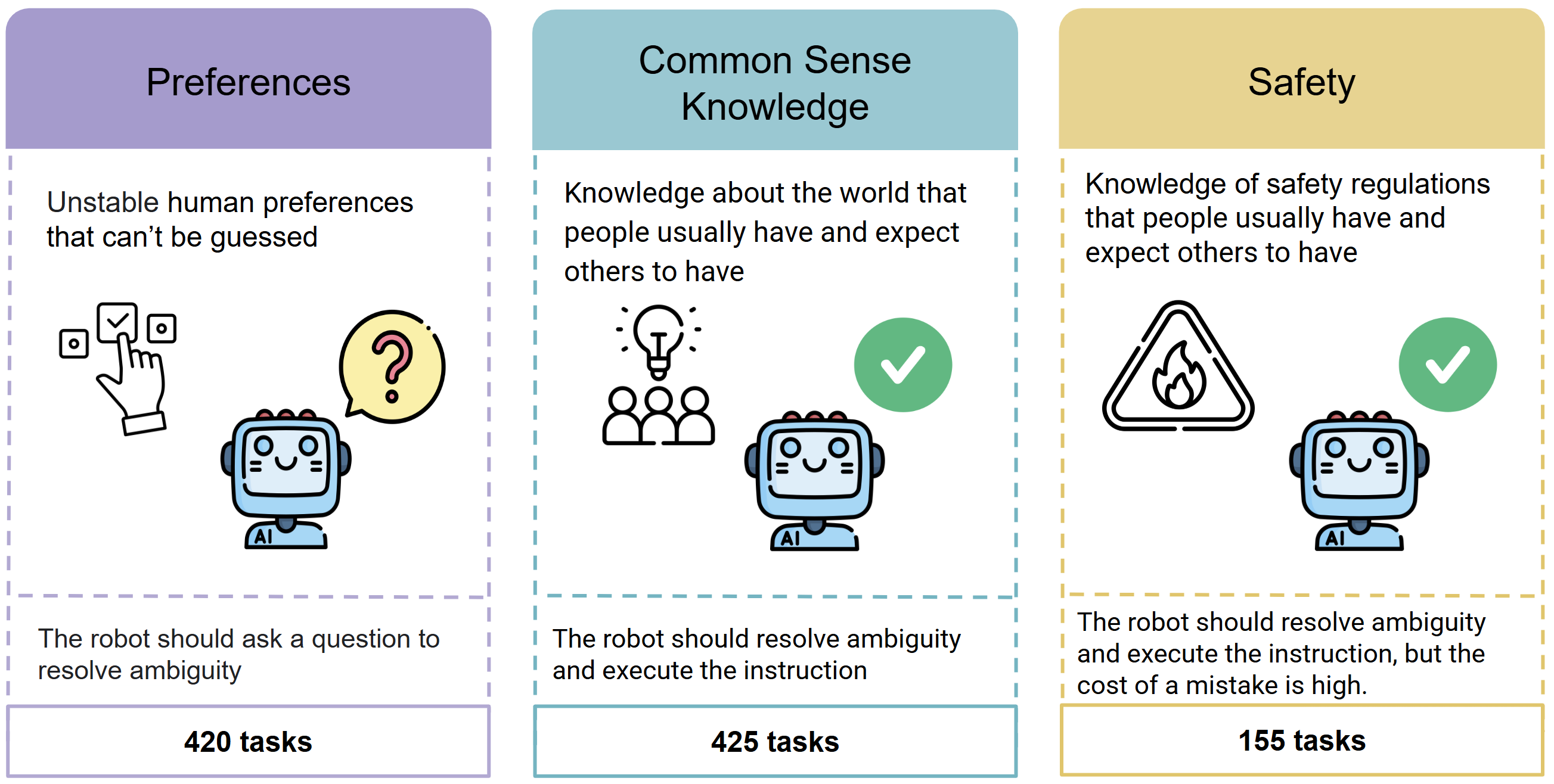
AmbiK: Dataset of Ambiguous Tasks in Kitchen EnvironmentAnastasiia Ivanova, Zoya Volovikova, Eva Bakaeva, and 2 more authorsIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025The use of Large Language Models (LLMs), which demonstrate impressive capabilities in natural language understanding and reasoning, in Embodied AI is a rapidly developing area. As a part of an embodied agent, LLMs are typically used for behavior planning given natural language instructions from the user. However, dealing with ambiguous instructions in real-world environments remains a challenge for LLMs. Various methods for task ambiguity detection have been proposed. However, it is difficult to compare them because they are tested on different datasets, and there is no universal benchmark. For this reason, we propose AmbiK (Ambiguous Tasks in Kitchen Environment), the fully textual dataset of ambiguous instructions addressed to a robot in a kitchen environment. AmbiK was collected with the assistance of LLMs and is human-validated. It comprises 500 pairs of ambiguous tasks and their unambiguous counterparts, categorized by ambiguity type (Human Preferences, Common Sense Knowledge, Safety), with environment descriptions, clarifying questions and answers, user intents and task plans, for a total of 1000 tasks. We hope that AmbiK will enable researchers to perform a unified comparison of ambiguity detection methods. The full dataset and the prompts used are available at: https://github.com/cog-model/AmbiK-dataset.
@inproceedings{ivanova_ambik_2025, dimensions = {true}, title = {{AmbiK}: {Dataset} of {Ambiguous} {Tasks} in {Kitchen} {Environment}}, url = {https://aclanthology.org/2025.acl-long.1593/}, booktitle = {Proceedings of the 63rd {Annual} {Meeting} of the {Association} for {Computational} {Linguistics} ({Volume} 1: {Long} {Papers})}, author = {Ivanova, Anastasiia and Volovikova, Zoya and Bakaeva, Eva and Kovalev, Alexey K and Panov, Aleksandr I}, year = {2025}, pages = {33216--33241} } -
 SegmATRon: Embodied Adaptive Semantic Segmentation for Indoor EnvironmentTatiana Zemskova, Margarita Kichik, Dmitry Yudin, and 2 more authorsNeurocomputing, 2025
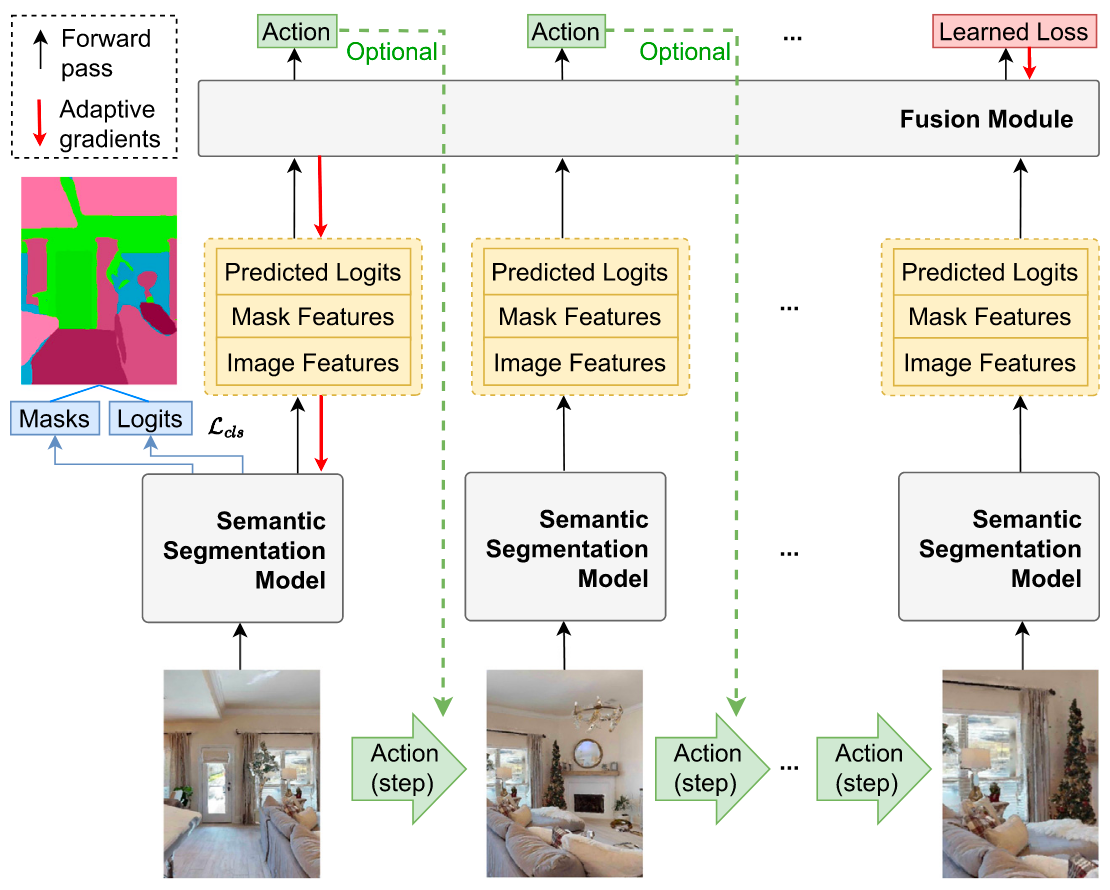
SegmATRon: Embodied Adaptive Semantic Segmentation for Indoor EnvironmentTatiana Zemskova, Margarita Kichik, Dmitry Yudin, and 2 more authorsNeurocomputing, 2025The state-of-the-art methods for computer vision are often trained with large amounts of data collected from static cameras. In contrast, an embodied intelligent agent can interact with a continuous environment to improve the perception quality. Previous methods for embodied computer vision have not considered the task of semantic segmentation. This paper first introduces an adaptive transformer model for embodied image semantic segmentation named SegmATRon. Its distinctive feature is the adaptation of model weights during inference on several images using a hybrid multicomponent loss function. We studied this model on datasets collected in the photorealistic Habitat and the synthetic AI2-THOR simulators. We showed that obtaining additional images using the agent’s actions in an indoor environment can improve the quality of semantic segmentation.
@article{zemskova_segmatron_2025, dimensions = {true}, title = {{SegmATRon}: {Embodied} {Adaptive} {Semantic} {Segmentation} for {Indoor} {Environment}}, volume = {638}, url = {https://www.sciencedirect.com/science/article/abs/pii/S0925231225008410}, doi = {10.1016/j.neucom.2025.130169}, journal = {Neurocomputing}, author = {Zemskova, Tatiana and Kichik, Margarita and Yudin, Dmitry and Staroverov, Aleksei and Panov, Aleksandr}, year = {2025}, pages = {130169} } - EAAIPolygon Decomposition for Obstacle Representation in Motion Planning with Model Predictive ControlAleksey Logunov, Muhammad Alhaddad, Konstantin Mironov, and 2 more authorsEngineering Applications of Artificial Intelligence, 2025
Model Predictive Control (MPC) is a powerful tool for planning the local trajectory of autonomous mobile robots. The paper considers a new algorithm for trajectory planning and obstacle avoidance based on the MPC technique known in Artificial Intelligence (AI) planning and robotics. We have proposed an original method for decomposing obstacles to form a potential field, which in turn is used as an additional component in MPC. Thus, we propose a new intelligent trajectory planning method that takes into account the special shape of obstacles, which in turn significantly improves the metrics of intelligent agent movement on the well-known Moving AI benchmark. The challenging aspect of MPC planning is collision avoidance on large and complicated grid maps. We propose the Polygon Segmentation for obtaining Artificial Potential Field (PolySAP). This local planner approximates the obstacles on the map with a set of polygons. We address the question of how to partition a map with polygons to make it fast and effective for a practical MPC planner. We propose a decomposition algorithm based on Straight Skeleton. Our algorithm returns a set of polygons, which are then convexified. Numerical experiments show that our method outperforms basic algorithms in performance and provides sufficient partition quality for effective planning. We propose an artificial potential function calculated for polygonal obstacles and added to the MPC objective for collision avoidance. We evaluate our approach on city map dataset and on a real robotic platform. Numerical experiments show that PolySAP allows for polygon decomposition that is five times faster than Interior Extensions. Our MPC solver provides a fast solution for the MPC task compared to the stateof-the-art MPC planners. Our planner ensured the safe motion of the real mobile robot through a narrow indoor environment. Our code is available at https://github.com/alhaddad-m/PolySAP.
@article{logunov_polygon_2025, dimensions = {true}, title = {Polygon {Decomposition} for {Obstacle} {Representation} in {Motion} {Planning} with {Model} {Predictive} {Control}}, volume = {153}, doi = {10.1016/j.engappai.2025.110690}, journal = {Engineering Applications of Artificial Intelligence}, author = {Logunov, Aleksey and Alhaddad, Muhammad and Mironov, Konstantin and Yakovlev, Konstantin and Panov, Aleksandr}, year = {2025}, pages = {110690} } - POGEMA: A Benchmark Platform for Cooperative Multi-Agent NavigationAlexey Skrynnik, Anton Andreychuk, Anatolii Borzilov, and 3 more authorsIn ICLR 2025, 2025
Multi-agent reinforcement learning (MARL) has recently excelled in solving challenging cooperative and competitive multi-agent problems in various environments with, mostly, few agents and full observability. Moreover, a range of crucial robotics-related tasks, such as multi-robot navigation and obstacle avoidance, that have been conventionally approached with the classical non-learnable methods (e.g., heuristic search) is currently suggested to be solved by the learning-based or hybrid methods. Still, in this domain, it is hard, not to say impossible, to conduct a fair comparison between classical, learning-based, and hybrid approaches due to the lack of a unified framework that supports both learning and evaluation. To this end, we introduce POGEMA, a set of comprehensive tools that includes a fast environment for learning, a generator of problem instances, the collection of pre-defined ones, a visualization toolkit, and a benchmarking tool that allows automated evaluation. We introduce and specify an evaluation protocol defining a range of domain-related metrics computed on the basics of the primary evaluation indicators (such as success rate and path length), allowing a fair multi-fold comparison. The results of such a comparison, which involves a variety of state-of-the-art MARL, search-based, and hybrid methods, are presented.
@inproceedings{skrynnik_pogema_2025, dimensions = {true}, title = {{POGEMA}: A Benchmark Platform for Cooperative Multi-Agent Navigation}, url = {https://openreview.net/forum?id=6VgwE2tCRm}, booktitle = {{ICLR} 2025}, author = {Skrynnik, Alexey and Andreychuk, Anton and Borzilov, Anatolii and Chernyavskiy, Alexander and Yakovlev, Konstantin and Panov, Aleksandr}, year = {2025} } - Learning Successor Features with Distributed Hebbian Temporal MemoryEvgenii Dzhivelikian, Petr Kuderov, and Aleksandr PanovIn ICLR 2025, 2025
This paper presents a novel approach to address the challenge of online sequence learning for decision making under uncertainty in non-stationary, partially observable environments. The proposed algorithm, Distributed Hebbian Temporal Memory (DHTM), is based on the factor graph formalism and a multi-component neuron model. DHTM aims to capture sequential data relationships and make cumulative predictions about future observations, forming Successor Features (SFs). Inspired by neurophysiological models of the neocortex, the algorithm uses distributed representations, sparse transition matrices, and local Hebbian-like learning rules to overcome the instability and slow learning of traditional temporal memory algorithms such as RNN and HMM. Experimental results show that DHTM outperforms LSTM, RWKV and a biologically inspired HMM-like algorithm, CSCG, on non-stationary data sets. Our results suggest that DHTM is a promising approach to address the challenges of online sequence learning and planning in dynamic environments.
@inproceedings{dzhivelikian_learning_2025, dimensions = {true}, title = {Learning Successor Features with Distributed Hebbian Temporal Memory}, url = {https://openreview.net/forum?id=wYJII5BRYU}, booktitle = {{ICLR} 2025}, author = {Dzhivelikian, Evgenii and Kuderov, Petr and Panov, Aleksandr}, year = {2025} } - Rethinking Exploration and Experience Exploitation in Value-Based Multi-Agent Reinforcement LearningAnatolii Borzilov, Alexey Skrynnik, and Aleksandr PanovIEEE Access, 2025
Cooperative Multi-Agent Reinforcement Learning (MARL) focuses on developing strategies to effectively train multiple agents to learn and adapt policies collaboratively. Despite being a relatively new area of research, most MARL methods are based on well-established approaches used in single-agent deep learning tasks due to their proven effectiveness. In this paper, we focus on the exploration problem inherent in many MARL algorithms. These algorithms often introduce new hyperparameters and incorporate auxiliary components, such as additional models, which complicate the adaptation process of the underlying RL algorithm to better fit multi-agent environments. We aim to optimize a deep MARL algorithm with minimal modifications to the well-known QMIX approach. Our investigation of the exploitation-exploration dilemma shows that the performance of state-of-the-art MARL algorithms can be matched by a simple modification of the ϵ-greedy policy. This modification depends on the ratio of available joint actions to the number of agents. We also improve the training aspect of the replay buffer to decorrelate experiences based on recurrent rollouts rather than episodes. The improved algorithm is not only easy to implement, but also aligns with state-of-theart methods without adding significant complexity. Our approach outperforms existing algorithms in four of seven scenarios across three distinct environments while remaining competitive in the other three.
@article{borzilov_rethinking_2025, dimensions = {true}, title = {Rethinking Exploration and Experience Exploitation in Value-Based Multi-Agent Reinforcement Learning}, volume = {13}, url = {https://ieeexplore.ieee.org/document/10844859}, doi = {10.1109/ACCESS.2025.3530974}, pages = {13770--13781}, journal = {IEEE Access}, author = {Borzilov, Anatolii and Skrynnik, Alexey and Panov, Aleksandr}, year = {2025} } - CSRApplying Opponent and Environment Modelling in Decentralised Multi-Agent Reinforcement LearningAlexander Chernyavskiy, Aleksandr Panov, and Aleksey SkrynnikCognitive Systems Research, 2025
Multi-agent reinforcement learning (MARL) has recently gained popularity and achieved much success in different kind of games such as zero-sum, cooperative or general-sum games. Nevertheless, the vast majority of modern algorithms assume information sharing during training and, hence, could not be utilised in decentralised applications as well as leverage high-dimensional scenarios and be applied to applications with general or sophisticated reward structure. Thus, due to collecting expenses and sparsity of data in realworld applications it becomes necessary to use world models to model the environment dynamics, using latent variables — i.e. use world model to generate synthetic data for training of MARL algorithms. Therefore, focusing on the paradigm of decentralised training and decentralised execution, we propose an extension to the model-based reinforcement learning approaches leveraging fully decentralised training with planning conditioned on neighbouring co-players’ latent representations. Our approach is inspired by the idea of opponent modelling. The method makes the agent learn in joint latent space without need to interact with the environment. We suggest the approach as proof of concept that decentralised model-based algorithms are able to emerge collective behaviour with limited communication during planning, and demonstrate its necessity on iterated matrix games and modified versions of StarCraft Multi-Agent Challenge (SMAC).
@article{chernyavskiy_applying_2025, dimensions = {true}, title = {Applying {Opponent} and {Environment} {Modelling} in {Decentralised} {Multi}-{Agent} {Reinforcement} {Learning}}, volume = {89}, url = {https://www.sciencedirect.com/science/article/abs/pii/S1389041724001001}, doi = {10.1016/j.cogsys.2024.101306}, journal = {Cognitive Systems Research}, author = {Chernyavskiy, Alexander and Panov, Aleksandr and Skrynnik, Aleksey}, year = {2025}, pages = {101306} } - AAAIMAPF-GPT: Imitation Learning for Multi-Agent Pathfinding at ScaleAnton Andreychuk, Konstantin Yakovlev, Aleksandr Panov, and 1 more authorIn AAAI 2025, 2025
Multi-agent pathfinding (MAPF) is a challenging computational problem that typically requires to find collision-free paths for multiple agents in a shared environment. Solving MAPF optimally is NP-hard, yet efficient solutions are critical for numerous applications, including automated warehouses and transportation systems. Recently, learning-based approaches to MAPF have gained attention, particularly those leveraging deep reinforcement learning. Following current trends in machine learning, we have created a foundation model for the MAPF problems called MAPF-GPT. Using imitation learning, we have trained a policy on a set of precollected sub-optimal expert trajectories that can generate actions in conditions of partial observability without additional heuristics, reward functions, or communication with other agents. The resulting MAPF-GPT model demonstrates zero-shot learning abilities when solving the MAPF problem instances that were not present in the training dataset. We show that MAPF-GPT notably outperforms the current best-performing learnable-MAPF solvers on a diverse range of problem instances and is efficient in terms of computation (in the inference mode).
@inproceedings{andreychuk_mapf-gpt_2025, dimensions = {true}, title = {{MAPF}-{GPT}: {Imitation} {Learning} for {Multi}-{Agent} {Pathfinding} at {Scale}}, booktitle = {{AAAI} 2025}, author = {Andreychuk, Anton and Yakovlev, Konstantin and Panov, Aleksandr and Skrynnik, Alexey}, year = {2025} } - AIJGenerative Models for Grid-Based and Image-Based PathfindingDaniil Kirilenko, Anton Andreychuk, Aleksandr I Panov, and 1 more authorArtificial Intelligence, 2025
Pathfinding is a challenging problem which generally asks to find a sequence of valid moves for an agent provided with a representation of the environment, i.e. a map, in which it operates. In this work, we consider pathfinding on binary grids and on image representations of the digital elevation models. In the former case, the transition costs are known, while in latter scenario, they are not. A widespread method to solve the first problem is to utilize a search algorithm that systematically explores the search space to obtain a solution. Ideally, the search should also be complemented with an informative heuristic to focus on the goal and prune the unpromising regions of the search space, thus decreasing the number of search iterations. Unfortunately, the widespread heuristic functions for grid-based pathfinding, such as Manhattan distance or Chebyshev distance, do not take the obstacles into account and in obstacle-rich environments demonstrate inefficient performance. As for pathfinding with image inputs, the heuristic search cannot be applied straightforwardly as the transition costs, i.e. the costs of moving from one pixel to the other, are not known. To tackle both challenges, we suggest utilizing modern deep neural networks to infer the instance-dependent heuristic functions at the pre-processing step and further use them for pathfinding with standard heuristic search algorithms. The principal heuristic function that we suggest learning is the path probability, which indicates how likely the grid cell (pixel) is lying on the shortest path (for binary grids with known transition costs, we also suggest another variant of the heuristic function that can speed up the search). Learning is performed in a supervised fashion (while we have also explored the possibilities of end-to-end learning that includes a planner in the learning pipeline). At the test time, path probability is used as the secondary heuristic for the Focal Search, a specific heuristic search algorithm that provides the theoretical guarantees on the cost bound of the resultant solution. Empirically, we show that the suggested approach significantly outperforms state-of-the-art competitors in a variety of different tasks (including out-of-the distribution instances).
@article{kirilenko_generative_2025, dimensions = {true}, title = {Generative Models for Grid-Based and Image-Based Pathfinding}, volume = {338}, url = {https://www.sciencedirect.com/science/article/abs/pii/S0004370224001747}, doi = {10.1016/j.artint.2024.104238}, journal = {Artificial Intelligence}, author = {Kirilenko, Daniil and Andreychuk, Anton and Panov, Aleksandr I and Yakovlev, Konstantin}, year = {2025} }




2024
- CSRHebbian Spatial Encoder with Adaptive Sparse ConnectivityPetr Kuderov, Evgenii Dzhivelikian, and Aleksandr PanovCognitive Systems Research, 2024
Biologically plausible neural networks have demonstrated efficiency in learning and recognizing patterns in data. This paper proposes a general online unsupervised algorithm for spatial data encoding using fast Hebbian learning. Inspired by the Hierarchical Temporal Memory (HTM) framework, we introduce the SpatialEncoder algorithm, which learns the spatial specialization of neurons’ receptive fields through Hebbian plasticity and k-WTA (k winners take all) inhibition. A key component of our model is a two-part synaptogenesis algorithm that enables the network to maintain a sparse connection matrix while adapting to non-stationary input data distributions. In the MNIST digit classification task, our model outperforms the HTM SpatialPooler in terms of classification accuracy and encoding stability. Compared to another baseline, a two-layer artificial neural network (ANN), our model achieves competitive classification accuracy with fewer iterations required for convergence. The proposed model offers a promising direction for future research on sparse neural networks with adaptive neural connectivity.
@article{kuderov_hebbian_2024, dimensions = {true}, volume = {88}, url = {https://www.sciencedirect.com/science/article/pii/S1389041724000718}, doi = {10.1016/j.cogsys.2024.101277}, journal = {Cognitive Systems Research}, author = {Kuderov, Petr and Dzhivelikian, Evgenii and Panov, Aleksandr}, year = {2024}, pages = {101277} } - ECAIInstruction Following with Goal-Conditioned Reinforcement Learning in Virtual EnvironmentsZoya Volovikova, Alexey Skrynnik, Petr Kuderov, and 1 more authorIn Frontiers in Artificial Intelligence and Applications, 2024
In this study, we address the issue of enabling an artificial intelligence agent to execute complex language instructions within virtual environments. In our framework, we assume that these instructions involve intricate linguistic structures and multiple interdependent tasks that must be navigated successfully to achieve the desired outcomes. To effectively manage these complexities, we propose a hierarchical framework that combines the deep language comprehension of large language models with the adaptive actionexecution capabilities of reinforcement learning agents: the language module (based on LLM) translates the language instruction into a high-level action plan, which is then executed by a pre-trained reinforcement learning agent.We have demonstrated the effectiveness of our approach in two different environments: in IGLU, where agents are instructed to build structures, and in Crafter, where agents perform tasks and interact with objects in the surrounding environment according to language commands.
@inproceedings{volovikova_instruction_2024, dimensions = {true}, title = {Instruction Following with Goal-Conditioned Reinforcement Learning in Virtual Environments}, volume = {392}, url = {https://ebooks.iospress.nl/volumearticle/69640}, doi = {10.3233/FAIA240545}, pages = {650--657}, booktitle = {Frontiers in Artificial Intelligence and Applications}, author = {Volovikova, Zoya and Skrynnik, Alexey and Kuderov, Petr and Panov, Aleksandr I}, year = {2024} } - RALFFStreams: Fast Search with Streams for Autonomous Maneuver PlanningMais Jamal, and Aleksandr PanovIEEE Robotics and Automation Letters, 2024
In autonomous driving, maneuver planning is essential for ride safety and comfort, involving both motion planning and decision-making. This paper introduces FFStreams, a novel approach combining high-level decision-making and low-level motion planning to solve maneuver planning problems while considering kinematic constraints. Addressed as an integrated Task and Motion Planning (TAMP) problem in a dynamic environment, the planner utilizes PDDL, incorporates Streams, and employs Fast-Forward heuristic search. Evaluated against baseline methods in challenging overtaking and lanechanging scenarios, FFStreams demonstrates superior performance, highlighting its potential for real-world applications.
@article{Jamal2024, dimensions = {true}, title = {FFStreams: Fast Search with Streams for Autonomous Maneuver Planning}, volume = {9}, url = {https://ieeexplore.ieee.org/document/10552884}, doi = {10.1109/LRA.2024.3412633}, pages = {6752--6759}, number = {7}, journal = {IEEE Robotics and Automation Letters}, author = {Jamal, Mais and Panov, Aleksandr}, year = {2024} } - IGPLSign-Based Image Criteria for Social Interaction Visual Question AnsweringAnfisa A Chuganskaya, Alexey K Kovalev, and Aleksandr I PanovLogic Journal of the IGPL, 2024
The multi-modal tasks have started to play a significant role in the research on Artificial Intelligence. A particular example of that domain is visuallinguistic tasks, such as Visual Question Answering. The progress of modern machine learning systems is determined, among other things, by the data on which these systems are trained. Most modern visual question answering datasets contain limited type questions that can be answered either by directly accessing the image itself or by using external data. At the same time, insufficient attention is paid to the issues of social interactions between people, which limits the scope of visual question answering systems. In this paper, we propose criteria by which images suitable for social interaction visual question answering can be selected for composing such questions, based on psychological research. We believe this should serve the progress of visual question answering systems.
@article{Chuganskaya2024, dimensions = {true}, title = {Sign-Based Image Criteria for Social Interaction Visual Question Answering}, volume = {32}, doi = {10.1093/jigpal/jzae026}, number = {3}, journal = {Logic Journal of the {IGPL}}, author = {Chuganskaya, Anfisa A and Kovalev, Alexey K and Panov, Aleksandr I}, year = {2024}, keywords = {mypub, mipt, airi, frccsc\_other, q2scopusprelim} } - ICRANeural Potential Field for Obstacle-Aware Local Motion PlanningMuhammad Alhaddad, Konstantin Mironov, Aleksey Staroverov, and 1 more authorIn 2024 IEEE International Conference on Robotics and Automation (ICRA), 2024
Model predictive control (MPC) may provide local motion planning for mobile robotic platforms. The challenging aspect is the analytic representation of collision cost for the case when both the obstacle map and robot footprint are arbitrary. We propose a Neural Potential Field: a neural network model that returns a differentiable collision cost based on robot pose, obstacle map, and robot footprint. The differentiability of our model allows its usage within the MPC solver. It is computationally hard to solve problems with a very high number of parameters. Therefore, our architecture includes neural image encoders, which transform obstacle maps and robot footprints into embeddings, which reduce problem dimensionality by two orders of magnitude. The reference data for network training are generated based on algorithmic calculation of a signed distance function. Comparative experiments showed that the proposed approach is comparable with existing local planners: it provides trajectories with outperforming smoothness, comparable path length, and safe distance from obstacles. Experiment on Husky UGV mobile robot showed that our approach allows real-time and safe local planning. The code for our approach is presented at https://github.com/cog-isa/NPField together with demo video.
@inproceedings{Alhaddad2024, dimensions = {true}, title = {Neural Potential Field for Obstacle-Aware Local Motion Planning}, booktitle = {2024 IEEE International Conference on Robotics and Automation (ICRA)}, author = {Alhaddad, Muhammad and Mironov, Konstantin and Staroverov, Aleksey and Panov, Aleksandr}, year = {2024} } - AAAIDecentralized Monte Carlo Tree Search for Partially Observable Multi-agent PathfindingAlexey Skrynnik, Anton Andreychuk, Konstantin Yakovlev, and 1 more authorIn Proceedings of the AAAI Conference on Artificial Intelligence, 2024
The Multi-Agent Pathfinding (MAPF) problem involves finding a set of conflict-free paths for a group of agents confined to a graph. In typical MAPF scenarios, the graph and the agents’ starting and ending vertices are known beforehand, allowing the use of centralized planning algorithms. However, in this study, we focus on the decentralized MAPF setting, where the agents may observe the other agents only locally and are restricted in communications with each other. Specifically, we investigate the lifelong variant of MAPF, where new goals are continually assigned to the agents upon completion of previous ones. Drawing inspiration from the successful AlphaZero approach, we propose a decentralized multi-agent Monte Carlo Tree Search (MCTS) method for MAPF tasks. Our approach utilizes the agent’s observations to recreate the intrinsic Markov decision process, which is then used for planning with a tailored for multi-agent tasks version of neural MCTS. The experimental results show that our approach outperforms state-of-theart learnable MAPF solvers. The source code is available at https://github.com/AIRI-Institute/mats-lp.
@inproceedings{Skrynnik2024b, dimensions = {true}, title = {Decentralized Monte Carlo Tree Search for Partially Observable Multi-agent Pathfinding}, volume = {38}, url = {https://ojs.aaai.org/index.php/AAAI/article/view/29703}, doi = {10.1609/aaai.v38i16.29703}, pages = {17531--17540}, booktitle = {Proceedings of the {AAAI} Conference on Artificial Intelligence}, author = {Skrynnik, Alexey and Andreychuk, Anton and Yakovlev, Konstantin and Panov, Aleksandr}, year = {2024}, keywords = {myconf, scopus, frccsc, airi, confastar} } - AAAILearn to Follow: Decentralized Lifelong Multi-Agent Pathfinding via Planning and LearningAlexey Skrynnik, Anton Andreychuk, Maria Nesterova, and 2 more authorsIn Proceedings of the AAAI Conference on Artificial Intelligence, 2024
Multi-agent Pathfinding (MAPF) problem generally asks to find a set of conflict-free paths for a set of agents confined to a graph and is typically solved in a centralized fashion. Conversely, in this work, we investigate the decentralized MAPF setting, when the central controller that possesses all the information on the agents’ locations and goals is absent and the agents have to sequentially decide the actions on their own without having access to the full state of the environment. We focus on the practically important lifelong variant of MAPF, which involves continuously assigning new goals to the agents upon arrival to the previous ones. To address this complex problem, we propose a method that integrates two complementary approaches: planning with heuristic search and reinforcement learning through policy optimization. Planning is utilized to construct and re-plan individual paths. We enhance our planning algorithm with a dedicated technique tailored to avoid congestion and increase the throughput of the system. We employ reinforcement learning to discover the collision avoidance policies that effectively guide the agents along the paths. The policy is implemented as a neural network and is effectively trained without any reward-shaping or external guidance. We evaluate our method on a wide range of setups comparing it to the state-of-the-art solvers. The results show that our method consistently outperforms the learnable competitors, showing higher throughput and better ability to generalize to the maps that were unseen at the training stage. Moreover our solver outperforms a rulebased one in terms of throughput and is an order of magnitude faster than a state-of-the-art search-based solver. The code is available at https://github.com/AIRI-Institute/learn-to-follow.
@inproceedings{Skrynnik2024, dimensions = {true}, title = {Learn to Follow: Decentralized Lifelong Multi-Agent Pathfinding via Planning and Learning}, volume = {38}, url = {https://ojs.aaai.org/index.php/AAAI/article/view/29704}, pages = {17541--17549}, booktitle = {Proceedings of the {AAAI} Conference on Artificial Intelligence}, author = {Skrynnik, Alexey and Andreychuk, Anton and Nesterova, Maria and Yakovlev, Konstantin and Panov, Aleksandr}, year = {2024}, keywords = {myconf, scopus, mipt, airi, 70-2021-00138, confastar} } - Object-Centric Learning with Slot Mixture ModuleDaniil Kirilenko, Vitaliy Vorobyov, Alexey Kovalev, and 1 more authorIn The Twelfth International Conference on Learning Representations, 2024
Object-centric architectures usually apply a differentiable module to the entire feature map to decompose it into sets of entity representations called slots. Some of these methods structurally resemble clustering algorithms, where the cluster’s center in latent space serves as a slot representation. Slot Attention is an example of such a method, acting as a learnable analog of the soft k-means algorithm. Our work employs a learnable clustering method based on the Gaussian Mixture Model. Unlike other approaches, we represent slots not only as centers of clusters but also incorporate information about the distance between clusters and assigned vectors, leading to more expressive slot representations. Our experiments demonstrate that using this approach instead of Slot Attention improves performance in object-centric scenarios, achieving state-of-the-art results in the set property prediction task.
@inproceedings{Kirilenko2024, dimensions = {true}, title = {Object-Centric Learning with Slot Mixture Module}, url = {https://openreview.net/forum?id=aBUidW4Nkd}, booktitle = {The Twelfth International Conference on Learning Representations}, author = {Kirilenko, Daniil and Vorobyov, Vitaliy and Kovalev, Alexey and Panov, Aleksandr}, year = {2024}, keywords = {myconf, frccsc, mipt, 20-71-10116, airi, confastar} } - Gradual Optimization Learning for Conformational Energy MinimizationArtem Tsypin, Leonid Ugadiarov, Kuzma Khrabrov, and 7 more authorsIn The Twelfth International Conference on Learning Representations, 2024
@inproceedings{Tsypin2024, dimensions = {true}, title = {Gradual Optimization Learning for Conformational Energy Minimization}, url = {https://openreview.net/forum?id=FMMF1a9ifL}, booktitle = {The Twelfth International Conference on Learning Representations}, author = {Tsypin, Artem and Ugadiarov, Leonid and Khrabrov, Kuzma and Telepov, Alexander and Rumiantsev, Egor and Skrynnik, Alexey and Panov, Aleksandr and Vetrov, Dmitry and Tutubalina, Elena and Kadurin, Artur}, year = {2024}, keywords = {myconf, frccsc, airi, confastar} } - EAAIHierarchical waste detection with weakly supervised segmentation in images from recycling plantsDmitry Yudin, Nikita Zakharenko, Artem Smetanin, and 7 more authorsEngineering Applications of Artificial Intelligence, 2024
Reducing environmental pollution with household waste and emissions from the computing clusters is an urgent technological problem. In our work, we explore both of these aspects: the deep learning application to improve the efficiency of waste recognition on recycling plant’s conveyor, as well as carbon dioxide emission from the computing devices used in this process. To conduct research, we developed an unique open WaRP dataset that demonstrates the best diversity among similar industrial datasets and contains more than 10,000 images with 28 different types of recyclable goods (bottles, glasses, card boards, cans, detergents, and canisters). Objects can overlap, be in poor lighting conditions, or significantly distorted. On the WaRP dataset, we study training and evaluation of cutting-edge deep neural networks for detection, classification and segmentation tasks. Additionally, we developed a hierarchical neural network approach called H-YC with weakly supervised waste segmentation. It provided a notable increase in the detection quality and made it possible to segment images, learning only having class labels, not their masks. Both the suggested hierarchical approach and the WaRP dataset have shown great industrial application potential.
@article{Yudin2024, dimensions = {true}, title = {Hierarchical waste detection with weakly supervised segmentation in images from recycling plants}, volume = {128}, issn = {0952-1976}, url = {https://www.sciencedirect.com/science/article/abs/pii/S0952197623017268}, doi = {10.1016/j.engappai.2023.107542}, pages = {107542}, journal = {Engineering Applications of Artificial Intelligence}, author = {Yudin, Dmitry and Zakharenko, Nikita and Smetanin, Artem and Filonov, Roman and Kichik, Margarita and Kuznetsov, Vladislav and Larichev, Dmitry and Gudov, Evgeny and Budennyy, Semen and Panov, Aleksandr}, urldate = {2023-11-20}, year = {2024}, keywords = {mypub, scopus, mipt, airi, q1scopusprelim} } - Interactive Semantic Map Representation for Skill-Based Visual Object NavigationTatiana Zemskova, Aleksei Staroverov, Kirill Muravyev, and 2 more authorsIEEE Access, 2024
Visual object navigation is one of the key tasks in mobile robotics. One of the most important components of this task is the accurate semantic representation of the scene, which is needed to determine and reach a goal object. This paper introduces a new representation of a scene semantic map formed during the embodied agent interaction with the indoor environment. It is based on a neural network method that adjusts the weights of the segmentation model with backpropagation of the predicted fusion loss values during inference on a regular (backward) or delayed (forward) image sequence. We implement this representation into a full-fledged navigation approach called SkillTron. The method can select robot skills from end-to-end policies based on reinforcement learning and classic map-based planning methods. The proposed approach makes it possible to form both intermediate goals for robot exploration and the final goal for object navigation. We conduct intensive experiments with the proposed approach in the Habitat environment, demonstrating its significant superiority over state-of-the-art approaches in terms of navigation quality metrics. The developed code and custom datasets are publicly available at github.com/AIRI-Institute/skill-fusion.
@article{Zemskova2024, dimensions = {true}, title = {Interactive Semantic Map Representation for Skill-Based Visual Object Navigation}, volume = {12}, issn = {2169-3536}, url = {https://ieeexplore.ieee.org/document/10477345}, doi = {10.1109/ACCESS.2024.3380450}, pages = {44628--44639}, journal = {{IEEE} Access}, author = {Zemskova, Tatiana and Staroverov, Aleksei and Muravyev, Kirill and Yudin, Dmitry and Panov, Aleksandr}, year = {2024}, keywords = {mypub, scopus, frccsc, mipt, 20-71-10116, airi, q1scopusprelim} } - TNNLSWhen to Switch: Planning and Learning For Partially Observable Multi-Agent PathfindingAlexey Skrynnik, Anton Andreychuk, Konstantin Yakovlev, and 1 more authorIEEE Transactions on Neural Networks and Learning Systems, 2024
@article{Skrynnik2023, dimensions = {true}, title = {When to Switch: Planning and Learning For Partially Observable Multi-Agent Pathfinding}, doi = {10.1109/TNNLS.2023.3303502}, pages = {17411-17424}, url = {https://ieeexplore.ieee.org/document/10236574}, journal = {{IEEE} Transactions on Neural Networks and Learning Systems}, shortjournal = {{TNNLS}}, author = {Skrynnik, Alexey and Andreychuk, Anton and Yakovlev, Konstantin and Panov, Aleksandr}, year = {2024}, volume = {35}, issue = {12}, keywords = {appl, group1} }
2023
- Fine-tuning Multimodal Transformer Models for Generating Actions in Virtual and Real EnvironmentsAleksei Staroverov, Andrey S Gorodetsky, Andrei S Krishtopik, and 3 more authorsIEEE Access, 2023
In this work, we propose and investigate an original approach to using a pre-trained multimodal transformer of a specialized architecture for controlling a robotic agent in an object manipulation task based on language instruction, which we refer to as RozumFormer. Our model is based on a bimodal (text-image) transformer architecture originally trained for solving tasks that use one or both modalities, such as language modeling, visual question answering, image captioning, text recognition, text-to-image generation, etc. The discussed model was adapted for robotic manipulation tasks by organizing the input sequence of tokens in a particular way, consisting of tokens for text, images, and actions. We demonstrated that such a model adapts well to new tasks and shows better results with fine-tuning than complete training in simulation and real environments. To transfer the model from the simulator to a real robot, new datasets were collected and annotated. In addition, experiments controlling the agent in a visual environment using reinforcement learning have shown that fine-tuning the model with a mixed dataset that includes examples from the initial visual-linguistic tasks only slightly decreases performance on these tasks, simplifying the addition of tasks from another domain.
@article{Staroverov2023, dimensions = {true}, title = {Fine-tuning Multimodal Transformer Models for Generating Actions in Virtual and Real Environments}, volume = {11}, url = {https://ieeexplore.ieee.org/document/10323309}, doi = {10.1109/ACCESS.2023.3334791}, pages = {130548--130559}, journal = {{IEEE} Access}, author = {Staroverov, Aleksei and Gorodetsky, Andrey S and Krishtopik, Andrei S and Yudin, Dmitry A and Kovalev, Alexey K and Panov, Aleksandr I}, year = {2023}, keywords = {mypub, scopus, frccsc, q1scopus, airi, mipt\_other, 70-2021-00138} } - AAAITransPath: Learning Heuristics For Grid-Based Pathfinding via TransformersDaniil Kirilenko, Anton Andreychuk, Aleksandr Panov, and 1 more authorIn Proceedings of the AAAI Conference on Artificial Intelligence, 2023
Heuristic search algorithms, e.g. A*, are the commonly used tools for pathfinding on grids, i.e. graphs of regular structure that are widely employed to represent environments in robotics, video games etc. Instance-independent heuristics for grid graphs, e.g. Manhattan distance, do not take the obstacles into account and, thus, the search led by such heuristics performs poorly in the obstacle-rich environments. To this end, we suggest learning the instance-dependent heuristic proxies that are supposed to notably increase the efficiency of the search. The first heuristic proxy we suggest to learn is the correction factor, i.e. the ratio between the instance independent cost-to-go estimate and the perfect one (computed offline at the training phase). Unlike learning the absolute values of the cost-to-go heuristic function, which was known before, when learning the correction factor the knowledge of the instance-independent heuristic is utilized. The second heuristic proxy is the path probability, which indicates how likely the grid cell is lying on the shortest path. This heuristic can be utilized in the Focal Search framework as the secondary heuristic, allowing us to preserve the guarantees on the bounded sub-optimality of the solution. We learn both suggested heuristics in a supervised fashion with the state-of-the-art neural networks containing attention blocks (transformers). We conduct a thorough empirical evaluation on a comprehensive dataset of planning tasks, showing that the suggested techniques i) reduce the computational effort of the A* up to a factor of \4\x while producing the solutions, which costs exceed the costs of the optimal solutions by less than \0.3\% on average; ii) outperform the competitors, which include the conventional techniques from the heuristic search, i.e. weighted A*, as well as the state-of-the-art learnable planners.
@inproceedings{Kirilenko2023, dimensions = {true}, title = {TransPath: Learning Heuristics For Grid-Based Pathfinding via Transformers}, volume = {37}, url = {https://ojs.aaai.org/index.php/AAAI/article/view/26465}, doi = {10.1609/aaai.v37i10.26465}, pages = {12436--12443}, booktitle = {Proceedings of the {AAAI} Conference on Artificial Intelligence}, author = {Kirilenko, Daniil and Andreychuk, Anton and Panov, Aleksandr and Yakovlev, Konstantin}, year = {2023}, keywords = {myconf, scopus, frccsc, airi, confastar} } - RALPolicy Optimization to Learn Adaptive Motion Primitives in Path Planning With Dynamic ObstaclesBrian Angulo, Aleksandr Panov, and Konstantin YakovlevIEEE Robotics and Automation Letters, 2023
This paper addresses the kinodynamic motion planning for non-holonomic robots in dynamic environments with both static and dynamic obstacles – a challenging problem that lacks a universal solution yet. One of the promising approaches to solve it is decomposing the problem into the smaller sub-problems and combining the local solutions into the global one. The crux of any planning method for non- holonomic robots is the generation of motion primitives that generates solutions to local planning sub-problems. In this work we introduce a novel learnable steering function (policy), which takes into account kinodynamic constraints of the robot and both static and dynamic obstacles. This policy is efficiently trained via the policy optimization. Empirically, we show that our steering function generalizes well to unseen problems. We then plug in the trained policy into the sampling-based and lattice-based planners, and evaluate the resultant POLAMP algorithm (Policy Optimization that Learns Adaptive Motion Primitives) in a range of challenging setups that involve a car-like robot operating in the obstacle-rich parking-lot en- vironments. We show that POLAMP is able to plan collision- free kinodynamic trajectories with success rates higher than 92%, when 50 simultaneously moving obstacles populate the environment showing better performance than the state-of-the- art competitors.
@article{Angulo2023, dimensions = {true}, title = {Policy Optimization to Learn Adaptive Motion Primitives in Path Planning With Dynamic Obstacles}, volume = {8}, issn = {2377-3766}, url = {https://ieeexplore.ieee.org/document/10003648/}, doi = {10.1109/LRA.2022.3233261}, pages = {824--831}, number = {2}, journal = {{IEEE} Robotics and Automation Letters}, author = {Angulo, Brian and Panov, Aleksandr and Yakovlev, Konstantin}, year = {2023}, eprint = {2212.14307}, keywords = {robotics, group1} } - NeuroInfoAddressing Task Prioritization in Model-based Reinforcement LearningArtem Zholus, Yaroslav Ivchenkov, and Aleksandr I PanovIn Advances in Neural Computation, Machine Learning, and Cognitive Research VI. NEUROINFORMATICS 2022. Studies in Computational Intelligence, 2023
World models facilitate sample-efficient reinforcement learning (RL) and, by design, can benefit from the multitask information. However, it is not used by typical model-based RL (MBRL) agents. We propose a data-centric approach to this problem. We build a controllable optimization process for MBRL agents that selectively prioritizes the data used by the model-based agent to improve its performance. We show how this can favor implicit task generalization in a custom environment based on MetaWorld with a parametric task variability. Furthermore, by bootstrapping the agent’s data, our method can boost the performance on unstable environments from DeepMind Control Suite. This is done without any additional data and architectural changes outperforming state-of-the-art visual model-based RL algorithms. Additionally, we frame the approach within the scope of methods that have unintentionally followed the controllable optimization process paradigm, filling the gap of the data-centric task-bootstrapping methods.
@inproceedings{Zholus2023, dimensions = {true}, title = {Addressing {Task} {Prioritization} in {Model}-based {Reinforcement} {Learning}}, booktitle = {Advances in Neural Computation, Machine Learning, and Cognitive Research VI. NEUROINFORMATICS 2022. Studies in Computational Intelligence}, author = {Zholus, Artem and Ivchenkov, Yaroslav and Panov, Aleksandr I}, editor = {Kryzhanovsky, B. and Dunin-Barkowski, W. and Redko, V. and Tiumentsev, Y.}, year = {2023}, pages = {19--30}, volume = {1064}, isbn = {978-3-031-19031-5}, url = {https://link.springer.com/10.1007/978-3-031-19032-2_3}, doi = {10.1007/978-3-031-19032-2_3}, keywords = {myconf, scopus, Reinforcement learning, frccsc, Model-based reinforcement learning, q4scopusprelim, airi, Generalization in RL, govgrant} } - ICONIPHPointLoc: Point-based Indoor Place Recognition using Synthetic RGB-D ImagesDmitry Yudin, Yaroslav Solomentsev, Ruslan Musaev, and 2 more authorsIn Neural Information Processing. Lecture Notes in Computer Science, 2023
We present a novel dataset named as HPointLoc, specially designed for exploring capabilities of visual place recognition in indoor environment and loop detection in simultaneous localization and mapping. The loop detection sub-task is especially relevant when a robot with an on-board RGB-D camera can drive past the same place (“Point") at different angles. The dataset is based on the popular Habitat simulator, in which it is possible to generate photorealistic indoor scenes using both own sensor data and open datasets, such as Matterport3D. To study the main stages of solving the place recognition problem on the HPointLoc dataset, we proposed a new modular approach named as PNTR. It first performs an image retrieval with the Patch-NetVLAD method, then extracts keypoints and matches them using R2D2, LoFTR or SuperPoint with SuperGlue, and finally performs a camera pose optimization step with TEASER++. Such a solution to the place recognition problem has not been previously studied in existing publications. The PNTR approach has shown the best quality metrics on the HPointLoc dataset and has a high potential for real use in localization systems for unmanned vehicles. The proposed dataset and framework are publicly available: https://github.com/metra4ok/HPointLoc.
@inproceedings{Yudin2023, dimensions = {true}, title = {HPointLoc: Point-based Indoor Place Recognition using Synthetic RGB-D Images}, volume = {13625}, url = {https://link.springer.com/chapter/10.1007/978-3-031-30111-7_40}, doi = {10.1007/978-3-031-30111-7_40}, booktitle = {Neural Information Processing. Lecture Notes in Computer Science}, author = {Yudin, Dmitry and Solomentsev, Yaroslav and Musaev, Ruslan and Staroverov, Aleksei and Panov, Aleksandr I}, editor = {Tanveer, Mohammad and Agarwal, Sonali and Ozawa, Seiichi and Ekbal, Asif and Jatowt, Adam}, year = {2023}, keywords = {dataset, indoor localization, rgb-d image, synthetic, visual place recognition}, pages = {471--484} } - Skill Fusion in Hybrid Robotic Framework for Visual Object Goal NavigationAleksei Staroverov, Kirill Muravyev, Konstantin Yakovlev, and 1 more authorRobotics, 2023
In recent years, Embodied AI has become one of the main topics in robotics. For the agent to operate in human-centric environments, it needs the ability to explore previously unseen areas and to navigate to objects that humans want the agent to interact with. This task, which can be formulated as ObjectGoal Navigation (ObjectNav), is the main focus of this work. To solve this challenging problem, we suggest a hybrid framework consisting of both not-learnable and learnable modules and a switcher between them—SkillFusion. The former are more accurate, while the latter are more robust to sensors’ noise. To mitigate the sim-to-real gap, which often arises with learnable methods, we suggest training them in such a way that they are less environment-dependent. As a result, our method showed top results in both the Habitat simulator and during the evaluations on a real robot. Video and code for our approach can be found on our website: https://github.com/AIRI-Institute/skill-fusion (accessed on 13 July 2023).
@article{Staroverov2024, dimensions = {true}, title = {Skill {Fusion} in {Hybrid} {Robotic} {Framework} for {Visual} {Object} {Goal} {Navigation}}, volume = {12}, issn = {2218-6581}, url = {https://www.mdpi.com/2218-6581/12/4/104}, doi = {10.3390/robotics12040104}, journal = {Robotics}, author = {Staroverov, Aleksei and Muravyev, Kirill and Yakovlev, Konstantin and Panov, Aleksandr I}, year = {2023} } - IJCAIObject-Oriented Decomposition of World Model in Reinforcement LearningLeonid Ugadiarov, and Aleksandr I PanovIn IJCAI Neuro-Symbolic Agents Workshop, 2023
Object-oriented models are expected to have better generalization abilities and operate on a more compact state representation. Recent studies have shown that using pre-trained object-centric representation learning models for state factorization in model-free algorithms improves the efficiency of policy learning. Approaches using object-factored world models to predict the environment dynamics have also shown their effectiveness in object-based grid-world environments. Following those works, we propose a novel object-oriented model-based value-based reinforcement learning algorithm Object Oriented Q-network (OOQN) employing an object-oriented decomposition of the world and state-value models. The results of the experiments demonstrate that the developed algorithm outperforms state-of-the-art model-free policy gradient algorithms and model-based value-based algorithm with a monolithic world model in tasks where individual dynamics of the objects is similar.
@inproceedings{Ugadiarov2023, dimensions = {true}, title = {Object-{Oriented} {Decomposition} of {World} {Model} in {Reinforcement} {Learning}}, booktitle = {IJCAI Neuro-Symbolic Agents Workshop}, author = {Ugadiarov, Leonid and Panov, Aleksandr I}, year = {2023} } - CVPRSegmATRon: Embodied Adaptive Semantic Segmentation for Indoor EnvironmentTatiana Zemskova, Margarita Kichik, Dmitry Yudin, and 1 more authorIn CVPR Workshop on Embodied AI, 2023
This paper presents an adaptive transformer model named SegmATRon for embodied image semantic segmentation. Its distinctive feature is the adaptation of model weights during inference on several images using a hybrid multicomponent loss function. We studied this model on datasets collected in the photorealistic Habitat Simulator. We showed that obtaining additional images using the agent’s actions in an indoor environment can improve the quality of semantic segmentation.
@inproceedings{Zemskova2023, dimensions = {true}, title = {SegmATRon: Embodied Adaptive Semantic Segmentation for Indoor Environment}, booktitle = {CVPR Workshop on Embodied AI}, author = {Zemskova, Tatiana and Kichik, Margarita and Yudin, Dmitry and Panov, Aleksandr}, year = {2023} }
2022
- CSRVector Semiotic Model for Visual Question AnsweringAlexey K. Kovalev, Makhmud Shaban, Evgeny Osipov, and 1 more authorCognitive Systems Research, 2022
In this paper, we propose a Vector Semiotic Model as a possible solution to the symbol grounding problem in the context of Visual Question Answering. The Vector Semiotic Model combines the advantages of a Semiotic Approach implemented in the Sign-Based World Model and Vector Symbolic Architectures. The Sign-Based World Model represents information about a scene depicted on an input image in a structured way and grounds abstract objects in an agent’s sensory input. We use the Vector Symbolic Architecture to represent the elements of the Sign-Based World Model on a computational level. Properties of a high-dimensional space and operations defined for high-dimensional vectors allow encoding the whole scene into a high-dimensional vector with the preservation of the structure. That leads to the ability to apply explainable reasoning to answer an input question. We conducted experiments are on a CLEVR dataset and show results comparable to the state of the art. The proposed combination of approaches, first, leads to the possible solution of the symbol-grounding problem and, second, allows expanding current results to other intelligent tasks (collaborative robotics, embodied intellectual assistance, etc.).
@article{Kovalev2021, dimensions = {true}, title = {Vector Semiotic Model for Visual Question Answering}, volume = {71}, issn = {1389-0417}, url = {https://www.sciencedirect.com/science/article/abs/pii/S1389041721000632}, doi = {10.1016/j.cogsys.2021.09.001}, pages = {52--63}, journal = {Cognitive Systems Research}, author = {Kovalev, Alexey K. and Shaban, Makhmud and Osipov, Evgeny and Panov, Aleksandr I.}, year = {2022} } - DokladyApplication of Pretrained Large Language Models in Embodied Artificial IntelligenceA. K. Kovalev, and Aleksandr I. PanovDoklady Mathematics, 2022
A feature of tasks in embodied artificial intelligence is that a query to an intelligent agent is formulated in natural language. As a result, natural language processing methods have to be used to transform the query into a format convenient for generating an appropriate action plan. There are two basic approaches to the solution of this problem. One is based on specialized models trained with particular instances of instructions translated into agent-executable format. The other approach relies on the ability of large language models trained with a large amount of unlabeled data to store common sense knowledge. As a result, such models can be used to generate an agent’s action plan in natural language without preliminary learning. This paper provides a detailed review of models based on the second approach as applied to embodied artificial intelli- gence tasks.
@article{Kovalev2022, dimensions = {true}, title = {Application of Pretrained Large Language Models in Embodied Artificial Intelligence}, volume = {106}, issn = {1064-5624}, url = {https://link.springer.com/10.1134/S1064562422060138}, doi = {10.1134/S1064562422060138}, pages = {S85--S90}, issue = {S1}, journal = {Doklady Mathematics}, author = {Kovalev, A. K. and Panov, Aleksandr I.}, year = {2022} } - BrainInfHierarchical intrinsically motivated agent planning behavior with dreaming in grid environmentsEvgenii Dzhivelikian, Artem Latyshev, Petr Kuderov, and 1 more authorBrain Informatics, 2022
Biologically plausible models of learning may provide a crucial insight for building autonomous intelligent agents capable of performing a wide range of tasks. In this work, we propose a hierarchical model of an agent operating in an unfamiliar environment driven by a reinforcement signal. We use temporal memory to learn sparse distributed representation of state–actions and the basal ganglia model to learn effective action policy on different levels of abstraction. The learned model of the environment is utilized to generate an intrinsic motivation signal, which drives the agent in the absence of the extrinsic signal, and through acting in imagination, which we call dreaming. We demonstrate that the proposed architecture enables an agent to effectively reach goals in grid environments.
@article{Dzhivelikian2022a, dimensions = {true}, title = {Hierarchical intrinsically motivated agent planning behavior with dreaming in grid environments}, volume = {9}, issn = {2198-4018}, url = {https://braininformatics.springeropen.com/articles/10.1186/s40708-022-00156-6}, doi = {10.1186/s40708-022-00156-6}, pages = {8}, number = {1}, journal = {Brain Informatics}, author = {Dzhivelikian, Evgenii and Latyshev, Artem and Kuderov, Petr and Panov, Aleksandr I}, year = {2022}, keywords = {slap, group1} } - DokladyPlanning and Learning in Multi-Agent Path FindingK. S. Yakovlev, A. A. Andreychuk, A. A. Skrynnik, and 1 more authorDoklady Mathematics, 2022
Multi-agent path finding arises, on the one hand, in numerous applied areas. A classical example is automated warehouses with a large number of mobile goods-sorting robots operating simultaneously. On the other hand, for this problem, there are no universal solution methods that simultaneously satisfy numerous (often contradictory) requirements. Examples of such criteria are a guarantee of finding optimal solu- tions, high-speed operation, the possibility of operation in partially observable environments, etc. This paper provides a survey of modern methods for multi-agent path finding. Special attention is given to various settings of the problem. The differences and between trainable and nontrainable solution methods and their applicability are discussed. Experimental programming environments necessary for implementing trainable approaches are analyzed separately.
@article{Yakovkev2022, dimensions = {true}, title = {Planning and Learning in Multi-Agent Path Finding}, volume = {106}, issn = {1064-5624}, url = {https://link.springer.com/10.1134/S1064562422060229}, doi = {10.1134/S1064562422060229}, pages = {S79--S84}, issue = {S1}, journal = {Doklady Mathematics}, author = {Yakovlev, K. S. and Andreychuk, A. A. and Skrynnik, A. A. and Panov, Aleksandr I.}, year = {2022}, keywords = {appl, group1} } - PeerJPathfinding in stochastic environments: learning vs planningAlexey Skrynnik, Anton Andreychuk, Konstantin Yakovlev, and 1 more authorPeerJ Computer Science, 2022
Among the main challenges associated with navigating a mobile robot in complex environments are partial observability and stochasticity. This work proposes a stochastic formulation of the pathfinding problem, assuming that obstacles of arbitrary shapes may appear and disappear at random moments of time. Moreover, we consider the case when the environment is only partially observable for an agent. We study and evaluate two orthogonal approaches to tackle the problem of reaching the goal under such conditions: planning and learning. Within planning, an agent constantly re-plans and upyears the path based on the history of the observations using a search-based planner. Within learning, an agent asynchronously learns to optimize a policy function using recurrent neural networks (we propose an original efficient, scalable approach). We carry on an extensive empirical evaluation of both approaches that show that the learning-based approach scales better to the increasing number of the unpredictably appearing/disappearing obstacles. At the same time, the planning-based one is preferable when the environment is close-to-the-deterministic ( i.e. , external disturbances are rare). Code available at https://github.com/Tviskaron/pathfinding-in-stochastic-envs .
@article{Skrynnik2022a, dimensions = {true}, title = {Pathfinding in stochastic environments: learning vs planning}, volume = {8}, issn = {2376-5992}, url = {https://peerj.com/articles/cs-1056}, doi = {10.7717/peerj-cs.1056}, pages = {e1056}, journal = {{PeerJ} Computer Science}, author = {Skrynnik, Alexey and Andreychuk, Anton and Yakovlev, Konstantin and Panov, Aleksandr}, year = {2022}, keywords = {appl, group1} } - Hierarchical Landmark Policy Optimization for Visual Indoor NavigationAleksei Staroverov, and Aleksandr PanovIEEE Access, 2022
In this paper, we study the problem of visual indoor navigation to an object that is defined by its semantic category. Recent works have shown significant achievements in the end-to-end reinforcement learning approach and modular systems. However, both approaches need a big step forward to be robust and practically applicable. To solve the problem of insufficient exploration of the scenes and make exploration more semantically meaningful, we extend standard task formulation and give the agent easily accessible landmarks in the form of the room locations and those types. The availability of landmarks allows the agent to build a hierarchical policy structure and achieve a success rate of 63% on validation scenes in a photo- realistic Habitat simulator. In a hierarchy, a low level consists of separately trained RL skills and a high level deterministic policy, which decides which skill is needed at the moment. Also, in this paper, we show the possibility of transferring a trained policy to a real robot. After a bit of training on the reconstructed real scene, the robot shows up to 79% SPL when solving the task of navigating to an arbitrary object.
@article{Staroverov2022, dimensions = {true}, title = {Hierarchical Landmark Policy Optimization for Visual Indoor Navigation}, volume = {10}, issn = {2169-3536}, url = {https://ieeexplore.ieee.org/document/9795006/}, doi = {10.1109/ACCESS.2022.3182803}, pages = {70447--70455}, journal = {{IEEE} Access}, author = {Staroverov, Aleksei and Panov, Aleksandr}, year = {2022}, keywords = {robotics, group1} }
2021
- LNCSLong-Term Exploration in Persistent MDPsLeonid Ugadiarov, Alexey Skrynnik, and Aleksandr I. PanovIn Advances in Soft Computing. MICAI 2021. Part I. Lecture Notes in Computer Science, 2021
Exploration is an essential part of reinforcement learning, which restricts the quality of learned policy. Hard-exploration environments are defined by huge state space and sparse rewards. In such conditions, an exhaustive exploration of the environment is often impossible, and the successful training of an agent requires a lot of interaction steps. In this paper, we propose an exploration method called Rollback-Explore (RbExplore), which utilizes the concept of the persistent Markov decision process, in which agents during training can roll back to visited states. We test our algorithm in the hard-exploration Prince of Persia game, without rewards and domain knowledge. At all used levels of the game, our agent outperforms or shows comparable results with state-of-the-art curiosity methods with knowledge-based intrinsic motivation: ICM and RND. An implementation of RbExplore can be found at https://github.com/cds-mipt/RbExplore.
@incollection{Ugadiarov2021, dimensions = {true}, title = {Long-Term Exploration in Persistent {MDPs}}, volume = {13067}, pages = {108--120}, booktitle = {Advances in Soft Computing. {MICAI} 2021. Part I. Lecture Notes in Computer Science}, publisher = {Springer}, author = {Ugadiarov, Leonid and Skrynnik, Alexey and Panov, Aleksandr I.}, editor = {Batyrshin, Ildar and Gelbukh, Alexander and Sidorov, Grigori}, year = {2021}, doi = {10.1007/978-3-030-89817-5_8} } - LNCSFlexible Data Augmentation in Off-Policy Reinforcement LearningAlexandra Rak, Alexey Skrynnik, and Aleksandr I PanovIn Artificial Intelligence and Soft Computing. ICAISC 2021. Lecture Notes in Computer Science, 2021
This paper explores an application of image augmentation in reinforcement learning tasks - a popular regularization technique in the computer vision area. The analysis is based on the model-free off-policy algorithms. As a regularization, we consider the augmentation of the frames that are sampled from the replay buffer of the model. Evaluated augmentation techniques are random changes in image contrast, random shifting, random cutting, and others. Research is done using the environments of the Atari games: Breakout, Space Invaders, Berzerk, Wizard of Wor, Demon Attack. Using augmentations allowed us to obtain results confirming the significant acceleration of the model’s algorithm convergence. We also proposed an adaptive mechanism for selecting the type of augmentation depending on the type of task being performed by the agent.
@incollection{Rak2021, dimensions = {true}, title = {Flexible Data Augmentation in Off-Policy Reinforcement Learning}, volume = {12854}, url = {https://www.scopus.com/record/display.uri?eid=2-s2.0-85117454790&origin=resultslist}, pages = {224--235}, booktitle = {Artificial Intelligence and Soft Computing. {ICAISC} 2021. Lecture Notes in Computer Science}, publisher = {Springer, Cham}, author = {Rak, Alexandra and Skrynnik, Alexey and Panov, Aleksandr I}, editor = {Rutkowski, L.}, year = {2021}, doi = {10.1007/978-3-030-87986-0_20} } - KBSForgetful experience replay in hierarchical reinforcement learning from expert demonstrationsAlexey Skrynnik, Aleksey Staroverov, Ermek Aitygulov, and 3 more authorsKnowledge-Based Systems, 2021
Deep reinforcement learning (RL) shows impressive results in complex gaming and robotic environments. These results are commonly achieved at the expense of huge computational costs and require an incredible number of episodes of interactions between the agent and the environment. Hierarchical methods and expert demonstrations are among the most promising approaches to improve the sample efficiency of reinforcement learning methods. In this paper, we propose a combination of methods that allow the agent to use low-quality demonstrations in complex vision-based environments with multiple related goals. Our Forgetful Experience Replay (ForgER) algorithm effectively handles expert data errors and reduces quality losses when adapting the action space and states representation to the agent’s capabilities. The proposed goal-oriented replay buffer structure allows the agent to automatically highlight sub-goals for solving complex hierarchical tasks in demonstrations. Our method has a high degree of versatility and can be integrated into various off-policy methods. The ForgER surpasses the existing state-of-the-art RL methods using expert demonstrations in complex environments. The solution based on our algorithm beats other solutions for the famous MineRL competition and allows the agent to demonstrate the behavior at the expert level.
@article{Skrynnik2021, dimensions = {true}, title = {Forgetful experience replay in hierarchical reinforcement learning from expert demonstrations}, volume = {218}, issn = {09507051}, url = {https://www.sciencedirect.com/science/article/abs/pii/S0950705121001076}, doi = {10.1016/j.knosys.2021.106844}, pages = {106844}, journal = {Knowledge-Based Systems}, author = {Skrynnik, Alexey and Staroverov, Aleksey and Aitygulov, Ermek and Aksenov, Kirill and Davydov, Vasilii and Panov, Aleksandr I.}, year = {2021}, keywords = {slap, group1} } - CSRHierarchical Deep Q-Network from imperfect demonstrations in MinecraftAlexey Skrynnik, Aleksey Staroverov, Ermek Aitygulov, and 3 more authorsCognitive Systems Research, 2021
We present hierarchical Deep Q-Network (HDQfD) that took first place in MineRL competition. HDQfD works on imperfect demonstrations utilize hierarchical structure of expert trajectories extracting effective sequence of meta-actions and subgoals. We introduce structured task dependent replay buffer and adaptive prioritizing technique that allow the HDQfD agent to gradually erase poor-quality expert data from the buffer. In this paper we present the details of the HDQfD algorithm and give the experimental results in Minecraft domain.
@article{Skrynnik2021a, dimensions = {true}, title = {Hierarchical Deep Q-Network from imperfect demonstrations in Minecraft}, volume = {65}, issn = {13890417}, url = {https://www.sciencedirect.com/science/article/pii/S1389041720300723}, doi = {10.1016/j.cogsys.2020.08.012}, pages = {74--78}, journal = {Cognitive Systems Research}, author = {Skrynnik, Alexey and Staroverov, Aleksey and Aitygulov, Ermek and Aksenov, Kirill and Davydov, Vasilii and Panov, Aleksandr I.}, year = {2021}, eprint = {1912.08664v2}, keywords = {slap, group1} } - LNCSApplying Vector Symbolic Architecture and Semiotic Approach to Visual DialogAlexey K Kovalev, Makhmud Shaban, Anfisa A. Chuganskaya, and 1 more authorIn Hybrid Artificial Intelligent Systems. HAIS 2021. Lecture Notes in Computer Science, 2021
The multi-modal tasks have started to play a significant role in the research on Artificial Intelligence. A particular example of that domain is visual-linguistic tasks, such as Visual Question Answering and its extension, Visual Dialog. In this paper, we concentrate on the Visual Dialog task and dataset. The task involves two agents. The first agent does not see an image and asks questions about the image content. The second agent sees this image and answers questions. The symbol grounding problem, or how symbols obtain their meanings, plays a crucial role in such tasks. We approach that problem from the semiotic point of view and propose the Vector Semiotic Architecture for Visual Dialog. The Vector Semiotic Architecture is a combination of the Sign-Based World Model and Vector Symbolic Architecture. The Sign-Based World Model represents agent knowledge on the high level of abstraction and allows uniform representation of different aspects of knowledge, forming a hierarchical representation of that knowledge in the form of a special kind of semantic network. The Vector Symbolic Architecture represents the computational level and allows to operate with symbols as with numerical vectors using simple element-wise operations. That combination enables grounding object representation from any level of abstraction to the sensory agent input.
@incollection{Kovalev2021b, dimensions = {true}, title = {Applying Vector Symbolic Architecture and Semiotic Approach to Visual Dialog}, volume = {12886}, isbn = {978-3-030-86270-1}, url = {https://www.scopus.com/record/display.uri?eid=2-s2.0-85115865440&origin=resultslist}, pages = {243--255}, booktitle = {Hybrid Artificial Intelligent Systems. {HAIS} 2021. Lecture Notes in Computer Science}, author = {Kovalev, Alexey K and Shaban, Makhmud and Chuganskaya, Anfisa A. and Panov, Aleksandr I.}, editor = {González, Hugo Sanjurjo and López, Iker Pastor and Bringa, Pablo García and Quintián, {SHéctor} and Corchado, Emilio}, year = {2021}, doi = {10.1007/978-3-030-86271-8_21}, keywords = {swm, group1} } - Hybrid Policy Learning for Multi-Agent PathfindingAlexey Skrynnik, Alexandra Yakovleva, Vasilii Davydov, and 2 more authorsIEEE Access, 2021
In this work we study the behavior of groups of autonomous vehicles, which are the part of the Internet ofVehicles systems. One of the challenging modes of operation of such systems is the case when the observability of each vehicle is limited and the global/local communication is unstable, e.g. in the crowded parking lots. In such scenarios the vehicles have to rely on the local observations and exhibit cooperative behavior to ensure safe and efficient trips. This type of problems can be abstracted to the so-called multi- agent pathfinding when a group of agents, confined to a graph, have to find collision-free paths to their goals (ideally, minimizing an objective function e.g. travel time). Widely used algorithms for solving this problem rely on the assumption that a central controller exists for which the full state of the environment (i.e. the agents current positions, their targets, configuration of the static obstacles etc.) is known and they cannot be straightforwardly be adapted to the partially-observable setups. To this end, we suggest a novel approach which is based on the decomposition of the problem into the two sub-tasks: reaching the goal and avoiding the collisions. To accomplish each of this task we utilize reinforcement learning methods such as Deep Monte Carlo Tree Search, Q-mixing networks, and policy gradients methods to design the policies that map the agents’ observations to actions. Next, we introduce the policy-mixing mechanism to end up with a single hybrid policy that allows each agent to exhibit both types of behavior – the individual one (reaching the goal) and the cooperative one (avoiding the collisions with other agents). We conduct an extensive empirical evaluation that shows that the suggested hybrid-policy outperforms standalone stat-of-the-art reinforcement learning methods for this kind of problems by a notable margin.
@article{Skrynnik2021b, dimensions = {true}, title = {Hybrid Policy Learning for Multi-Agent Pathfinding}, volume = {9}, issn = {2169-3536}, url = {https://ieeexplore.ieee.org/document/9532001/}, doi = {10.1109/ACCESS.2021.3111321}, pages = {126034--126047}, journal = {{IEEE} Access}, author = {Skrynnik, Alexey and Yakovleva, Alexandra and Davydov, Vasilii and Yakovlev, Konstantin and Panov, Aleksandr I.}, year = {2021}, keywords = {appl, group1} } - LNCSAdaptive Maneuver Planning for Autonomous Vehicles Using Behavior Tree on Apollo PlatformMais Jamal, and Aleksandr PanovIn Artificial Intelligence XXXVIII. SGAI 2021. Lecture Notes in Computer Science, 2021
In safety-critical systems such as autonomous driving sys- tems, behavior planning is a significant challenge. The presence of numerous dynamic obstacles makes the driving environment unpredictable. The planning algorithm should be safe, reactive, and adaptable to environmental changes. The paper presents an adaptive maneuver planning algorithm based on an evolving behavior tree created with genetic programming. In addition, we make a technical contribution to the Baidu Apollo autonomous driving platform, allowing the platform to test and develop overtaking maneuver planning algorithms.
@incollection{Jamal2021, dimensions = {true}, title = {Adaptive Maneuver Planning for Autonomous Vehicles Using Behavior Tree on Apollo Platform}, volume = {13101}, url = {https://link.springer.com/10.1007/978-3-030-91100-3_26}, pages = {327--340}, booktitle = {Artificial Intelligence {XXXVIII}. {SGAI} 2021. Lecture Notes in Computer Science}, author = {Jamal, Mais and Panov, Aleksandr}, editor = {Bramer, Max and Ellis, Richard}, year = {2021}, doi = {10.1007/978-3-030-91100-3_26}, keywords = {robotics, group1} } - LNCSQ-Mixing Network for Multi-agent Pathfinding in Partially Observable Grid EnvironmentsVasilii Davydov, Alexey Skrynnik, Konstantin Yakovlev, and 1 more authorIn Artificial Intelligence. RCAI 2021. Lecture Notes in Computer Science, 2021
In this paper, we consider the problem of multi-agent navigation in partially observable grid environments. This problem is challenging for centralized planning approaches as they typically rely on full knowledge of the environment. To this end, we suggest utilizing the reinforcement learning approach when the agents first learn the policies that map observations to actions and then follow these policies to reach their goals. To tackle the challenge associated with learning cooperative behavior, i.e. in many cases agents need to yield to each other to accomplish a mission. We use a mixing Q-network that complements learning individual policies. In the experimental evaluation, we show that such approach leads to plausible results and scales well to a large number of agents.
@incollection{Davydov2021, dimensions = {true}, title = {Q-Mixing Network for Multi-agent Pathfinding in Partially Observable Grid Environments}, volume = {12948}, isbn = {978-3-030-86854-3}, pages = {169--179}, booktitle = {Artificial Intelligence. {RCAI} 2021. Lecture Notes in Computer Science}, publisher = {Springer}, author = {Davydov, Vasilii and Skrynnik, Alexey and Yakovlev, Konstantin and Panov, Aleksandr}, editor = {Kovalev, Sergei M. and Kuznetsov, Sergei O. and Panov, Aleksandr I.}, year = {2021}, eprint = {2108.06148}, doi = {10.1007/978-3-030-86855-0_12}, keywords = {appl, group1} }
2020
- Real-Time Object Navigation with Deep Neural Networks and Hierarchical Reinforcement LearningAleksey Staroverov, Dmitry A. Yudin, Ilya Belkin, and 3 more authorsIEEE Access, 2020
In the last years, deep learning and reinforcement learning methods have significantly improved mobile robots in such fields as perception, navigation, and planning. But there are still gaps in applying these methods to real robots due to the low computational efficiency of recent neural network architectures and their poor adaptability to robotic experiments’ realities. In this paper, we consider an important task in mobile robotics - navigation to an object using an RGB-D camera.We develop a new neural network framework for robot control that is fast and resistant to possible noise in sensors and actuators. We propose an original integration of semantic segmentation, mapping, localization, and reinforcement learning methods to improve the effectiveness of exploring the environment, finding the desired object, and quickly navigating to it. We created a new HISNav dataset based on the Habitat virtual environment, which allowed us to use simulation experiments to pre-train the model and then upload it to a real robot. Our architecture is adapted to work in a real-time environment and fully implements modern trends in this area.
@article{Staroverov2020b, dimensions = {true}, title = {Real-Time Object Navigation with Deep Neural Networks and Hierarchical Reinforcement Learning}, volume = {8}, issn = {2169-3536}, url = {https://ieeexplore.ieee.org/document/9241850/}, doi = {10.1109/ACCESS.2020.3034524}, pages = {195608--195621}, journal = {{IEEE} Access}, author = {Staroverov, Aleksey and Yudin, Dmitry A. and Belkin, Ilya and Adeshkin, Vasily and Solomentsev, Yaroslav K. and Panov, Aleksandr I.}, year = {2020}, keywords = {robotics, group1} }
2019
- LNCSMental Actions and Modelling of Reasoning in Semiotic Approach to AGIAlexey K Kovalev, and Aleksandr I PanovIn Artificial General Intelligence. AGI 2019. Lecture Notes in Computer Science, 2019
The article expounds the functional of a cognitive architecture Sign-Based World Model (SBWM) through the algorithm for the implementation of a particular case of reasoning. The SBWM architecture is a multigraph, called a semiotic network with special rules of activation spreading. In a semiotic network, there are four subgraphs that have specific properties and are composed of constituents of the main SBWM element – the sign. Such subgraphs are called causal networks on images, significances, personal meanings, and names. The semiotic network can be viewed as the memory of an intelligent agent. It is proposed to divide the agent’s memory in the SBWM architecture into a long-term memory consisting of signs-prototype, and a working memory consisting of signs-instance. The concept of elementary mental actions is introduced as an integral part of the reasoning process. Examples of such actions are provided. The performance of the proposed reasoning algorithm is considered by a model example.
@inproceedings{Kovalev2019, dimensions = {true}, title = {Mental Actions and Modelling of Reasoning in Semiotic Approach to {AGI}}, volume = {11654}, isbn = {978-3-030-27005-6}, url = {https://link.springer.com/chapter/10.1007/978-3-030-27005-6_12}, doi = {10.1007/978-3-030-27005-6_12}, pages = {121--131}, booktitle = {Artificial General Intelligence. {AGI} 2019. Lecture Notes in Computer Science}, publisher = {Springer}, author = {Kovalev, Alexey K and Panov, Aleksandr I}, editor = {Hammer, Patrick and Agrawal, Pulin and Goertzel, Ben and Iklé, Matthew}, year = {2019}, keywords = {swm, group1} } - LNCSHierarchical Psychologically Inspired Planning for Human-Robot Interaction TasksGleb Kiselev, and Aleksandr PanovIn Interactive Collaborative Robotics. ICR 2019. Lecture Notes in Computer Science, 2019
This paper presents a new algorithm for hierarchical case-based behavior planning in a coalition of agents – HierMAP. The considered algorithm, in contrast to the well-known planners HEART, PANDA, and others, is intended primarily for use in multi-agent tasks. For this, the possibility of dynamically distributing agent roles with different functionalities was realized. The use of a psychologically plausible approach to the representation of the knowledge by agents using a semiotic network allows applying HierMAP in groups in which people participate as one of the actors. Thus, the algorithm allows us to represent solutions of collaborative problems, forming human- interpretable results at each planning step. Another advantage of the proposed method is the ability to save and reuse experience of planning – expansion in the field of case-based planning. Such extension makes it possible to consider information about the success/ failure of interaction with other members of the coalition. Presenting precedents as a special part of the agent’s memory (semantic network on meanings) allows to significantly reduce the planning time for a similar class of tasks. The paper deals with smart relocation tasks in the environment. A comparison is made with the main hierarchical planners widely used at present.
@inproceedings{Kiselev2019, dimensions = {true}, title = {Hierarchical Psychologically Inspired Planning for Human-Robot Interaction Tasks}, volume = {11659}, isbn = {978-3-030-26118-4}, url = {https://doi.org/10.1007/978-3-030-26118-4_15}, doi = {10.1007/978-3-030-26118-4_15}, pages = {150--160}, booktitle = {Interactive Collaborative Robotics. {ICR} 2019. Lecture Notes in Computer Science}, publisher = {Springer}, author = {Kiselev, Gleb and Panov, Aleksandr}, editor = {Ronzhin, Andrey and Rigoll, Gerhard and Meshcheryakov, Roman}, year = {2019}, keywords = {swm, group1} } - STIPGoal Setting and Behavior Planning for Cognitive AgentsAleksandr I. PanovScientific and Technical Information Processing, 2019
@article{Panov2019, dimensions = {true}, title = {Goal Setting and Behavior Planning for Cognitive Agents}, volume = {46}, url = {https://link.springer.com/article/10.3103/S0147688219060066}, doi = {10.3103/S0147688219060066}, pages = {404--415}, number = {6}, journal = {Scientific and Technical Information Processing}, author = {Panov, Aleksandr I.}, year = {2019}, keywords = {swm, group1} } - OMNNObject Detection with Deep Neural Networks for Reinforcement Learning in the Task of Autonomous Vehicles Path Planning at the IntersectionD A Yudin, A Skrynnik, A Krishtopik, and 2 more authorsOptical Memory and Neural Networks, 2019
Among a number of problems in the behavior planning of an unmanned vehicle the central one is movement in difficult areas. In particular, such areas are intersections at which direct interac- tion with other road agents takes place. In our work, we offer a new approach to train of the intelligent agent that simulates the behavior of an unmanned vehicle, based on the integration of reinforcement learning and computer vision. Using full visual information about the road intersection obtained from aerial photographs, it is studied automatic detection the relative positions of all road agents with vari- ous architectures of deep neural networks (YOLOv3, Faster R-CNN, RetinaNet, Cascade R-CNN, Mask R-CNN, Cascade Mask R-CNN). The possibilities of estimation of the vehicle orientation angle based on a convolutional neural network are also investigated. Obtained additional features are used in the modern effective reinforcement learning methods of Soft Actor Critic and Rainbow, which allows to accelerate the convergence of its learning process. To demonstrate the operation of the devel- oped system, an intersection simulator was developed, at which a number of model experiments were carried out.
@article{Yudin2019, dimensions = {true}, title = {Object Detection with Deep Neural Networks for Reinforcement Learning in the Task of Autonomous Vehicles Path Planning at the Intersection}, volume = {28}, issn = {1060-992X}, url = {https://link.springer.com/article/10.3103%2FS1060992X19040118}, doi = {10.3103/S1060992X19040118}, pages = {283--295}, number = {4}, journal = {Optical Memory and Neural Networks}, author = {Yudin, D A and Skrynnik, A and Krishtopik, A and Belkin, I and Panov, Aleksandr I.}, year = {2019}, keywords = {robotics, group1} } - LNCSToward Faster Reinforcement Learning for Robotics : Using Gaussian ProcessesAli Younes, and Aleksandr I PanovIn RAAI Summer School 2019. Lecture Notes in Computer Science, 2019
Standard robotic control works perfectly in case of ordinary conditions, but in the case of a change in the conditions (e.g. damaging of one of the motors), the robot won’t achieve its task anymore. We need an algorithm that provide the robot with the ability of adaption to unforeseen situations. Reinforcement learning provide a framework corresponds with that requirements, but it needs big data sets to learn robotic tasks, which is impractical. We discuss using Gaussian processes to improve the efficiency of the Reinforcement learning, where a Gaussian Process will learn a state transition model using data from the robot (interaction) phase, and after that use the learned GP model to simulate trajectories and optimize the robot’s controller in a (simulation) phase. PILCO algorithm considered as the most data efficient RL algorithm. It gives promising results in Cart-pole task, where a working controller was learned after seconds of (interaction) on the real robot, but the whole training time, considering the training in the (simulation) was longer. In this work, we will try to leverage the abilities of the computational graphs to produce a ROS friendly python implementation of PILCO, and discuss a case study of a real world robotic task.
@incollection{Younes2019, dimensions = {true}, title = {Toward Faster Reinforcement Learning for Robotics : Using Gaussian Processes}, volume = {11866}, url = {https://link.springer.com/chapter/10.1007%2F978-3-030-33274-7_11}, pages = {160--174}, booktitle = {{RAAI} Summer School 2019. Lecture Notes in Computer Science}, publisher = {Springer}, author = {Younes, Ali and Panov, Aleksandr I}, editor = {Osipov, Gennady S. and Panov, Aleksandr I. and Yakovlev, Konstantin S.}, year = {2019}, doi = {10.1007/978-3-030-33274-7_11}, keywords = {robotics, group1} }
2018
- LNCSTask and Spatial Planning by the Cognitive Agent with Human-like Knowledge RepresentationErmek Aitygulov, Gleb Kiselev, and Aleksandr I. PanovIn Interactive Collaborative Robotics. ICR 2018. Lecture Notes in Computer Science, 2018
The paper considers the task of simultaneous learning and planning actions for moving a cognitive agent in two-dimensional space. Planning is carried out by an agent who uses an anthropic way of knowledge representation that allows him to build transparent and understood planes, which is especially important in case of human-machine interaction. Learning actions to manipulate objects is carried out through reinforcement learning and demonstrates the possibilities of replenishing the agent’s procedural knowledge. The presented approach was demonstrated in an experiment in the Gazebo simulation environment.
@inproceedings{Kiselev2018c, dimensions = {true}, title = {Task and Spatial Planning by the Cognitive Agent with Human-like Knowledge Representation}, volume = {11097}, isbn = {978-3-319-99582-3}, url = {https://link.springer.com/chapter/10.1007/978-3-319-99582-3_1}, doi = {10.1007/978-3-319-99582-3_1}, pages = {1--12}, booktitle = {Interactive Collaborative Robotics. {ICR} 2018. Lecture Notes in Computer Science}, publisher = {Springer}, author = {Aitygulov, Ermek and Kiselev, Gleb and Panov, Aleksandr I.}, editor = {Ronzhin, A. and Rigoll, G. and Meshcheryakov, R.}, year = {2018}, keywords = {slap, group1} }
2017
- LNCSSynthesis of the Behavior Plan for Group of Robots with Sign Based World ModelGleb A. Kiselev, and Aleksandr I. PanovIn Interactive Collaborative Robotics. ICR 2017. Lecture Notes in Computer Science, 2017
The paper considers the task of the group’s collective plan intellectual agents. Robotic systems are considered as agents, possessing a manipulator and acting with objects in a determined external environment. The MultiMAP planning algorithm proposed in the article is hierarchical. It is iterative and based on the original sign representation of knowledge about objects and processes, agents knowledge about themselfs and about other members of the group. For distribution actions between agents in general plan signs “I” and “Other” (“They”) are used. In conclusion, the results of experiments in the model problem “Blocksworld” for a group of several agents are presented.
@inproceedings{Kiselev2017a, dimensions = {true}, title = {Synthesis of the Behavior Plan for Group of Robots with Sign Based World Model}, volume = {10459}, isbn = {978-3-319-66470-5}, url = {https://link.springer.com/chapter/10.1007/978-3-319-66471-2_10}, doi = {10.1007/978-3-319-66471-2_10}, pages = {83--94}, booktitle = {Interactive Collaborative Robotics. {ICR} 2017. Lecture Notes in Computer Science}, publisher = {Springer}, author = {Kiselev, Gleb A. and Panov, Aleksandr I.}, editor = {Ronzhin, A. and Rigoll, G. and Meshcheryakov, R.}, year = {2017}, keywords = {robotics, group1} }
2016
- CSRMultilayer cognitive architecture for UAV controlStanislav Emel’yanov, Dmitry Makarov, Aleksandr I. Panov, and 1 more authorCognitive Systems Research, 2016
Extensive use of unmanned aerial vehicles (UAVs) in recent years has induced the rapid growth of research areas related to UAV production. Among these, the design of control systems capable of automating a wide range of UAV activities is one of the most actively explored and evolving. Currently, researchers and developers are interested in designing control systems that can be referred to as intelligent, e.g. the systems which are suited to solve such tasks as planning, goal prioritization, coalition formation etc. and thus guarantee high levels of UAV autonomy. One of the principal problems in intelligent control system design is tying together various methods and models traditionally used in robotics and aimed at solving such tasks as dynamics modelling, control signal genera- tion, location and mapping, path planning etc. with the methods of behaviour modelling and planning which are thoroughly studied in cognitive science. Our work is aimed at solving this problem. We propose layered architecture — STRL (strategic, tactical, reactive, layered) — of the control system that au- tomates the behaviour generation using a cognitive approach while taking into account complex dynamics and kinematics of the control object (UAV).We use a special type of knowledge representation — sign world model — that is based on the psychological activity theory to describe individual behaviour planning and coalition formation processes. We also propose path planning methodology which serves as the mediator between the high-level cognitive activities and the reactive control signals generation. To generate these signals we use a state-dependent Riccati equation and specific method for solving it. We believe that utilization of the proposed architecture will broaden the spectrum of tasks which can be solved by the UAV’s coalition automatically, as well as raise the autonomy level of each individual member of that coalition.
@article{Emelyanov2016, dimensions = {true}, title = {Multilayer cognitive architecture for {UAV} control}, volume = {39}, issn = {1389-0417}, url = {https://www.sciencedirect.com/science/article/abs/pii/S1389041716000048}, doi = {10.1016/j.cogsys.2015.12.008}, pages = {58--72}, journal = {Cognitive Systems Research}, author = {Emel’yanov, Stanislav and Makarov, Dmitry and Panov, Aleksandr I. and Yakovlev, Konstantin}, year = {2016}, keywords = {strl, group1} }
2014
- JCSCBehavior control as a function of consciousness. I. World model and goal settingG. S. Osipov, A. I. Panov, and N. V. ChudovaJournal of Computer and Systems Sciences International, 2014
Functions that are referred in psychology as functions of consciousness are considered. These functions include reflection, consciousness of activity motivation, goal setting, synthesis of goal oriented behavior, and some others. The description is based on the concept of sign, which is widely used in psychology and, in particular, in the cultural-historical theory by Vygotsky, in which sign is interpreted informally. In this paper, we elaborate upon the concept of sign, consider mechanisms of sign formation, and some self-organization on the set of signs. Due to the work of self-organization mechanisms, a new method for the representation of the world model of an actor appears. The concept of semiotic network is introduced that is used for the examination of the actor’s world models. Models of some functions indicated above are constructed. The second part of the paper is devoted to functions of self-consciousness and to the application of the constructed models for designing plans and constructing new architectures of intelligent agents that are able, in particular, to distribute roles in coalitions.
@article{Osipov2014b, dimensions = {true}, title = {Behavior control as a function of consciousness. I. World model and goal setting}, volume = {53}, issn = {1064-2307}, url = {http://link.springer.com/10.1134/S1064230714040121}, doi = {10.1134/S1064230714040121}, pages = {517--529}, number = {4}, journal = {Journal of Computer and Systems Sciences International}, author = {Osipov, G. S. and Panov, A. I. and Chudova, N. V.}, urlyear = {2014-09-29}, year = {2014}, keywords = {swm, group1} }